昨日は、西村さんよりAurora移行大全#2 でした。ドキドキの移行が無事成功して嬉しいですね。 engineer.retty.me
Retty Advent Calendar も終わりが近づいてきました。 24日目の本日はデータ基盤について紹介します

data-platform-meetup.connpass.com
今回の記事は、先日登壇した以下のイベントで発表を行いました。 コミュニティの盛り上がりを感じる良いミートアップだったと思います。
この記事では発表ではお話しできなかったことの補足も含め、 我々のデータ基盤を取り巻く構成と その背景となる考え方について紹介したいと思います。
誰のためのデザイン?
分析、という行いは決してアナリストのためだけのものではなく プロダクト開発に従事する人々すべてにとって大事なものです。
「推測するな計測せよ」とは開発者にとっても馴染み深い言葉でもありますが データ基盤開発は、まさに計測のためのシステム開発と言い換えて良いでしょう。 作るべきものが明確になっていないプロダクト開発という性質上、観察や計測といった試行錯誤 に関心が寄るのは自然の流れといえます。
データ基盤のアーキテクチャを考える上で、そのアーキテクチャはいったい 「誰のためのものか?」を考えることはよい洞察を得るためのヒントとなります。
データの民主化と基盤開発
データ基盤開発におけるトピックは、構成要素の技術的実現難易度が高いものであることからほんの数年前で取り上げられる対象は技術的トピックが取り扱われることがほとんどだったように思います。
最近では、BigQueryをはじめとするマネージドサービスの普及が進み データ利用に焦点が当たるようになりデータ基盤開発のための文化的実現に対する トピックも取り扱われることも多くなりました。
その代表的なテーマにデータの民主化があります。 民主化という言葉は「自由に触れられるデータや人を増やす」ことを目的においているように聞こえますが、その主旨はデータにより多様な観点を取り入れることにあります。 データ自身はある時点の事実を示すのみで、効果的なデータ利用のため最も大事になるのはそのデータへの問いかけ方です。 よりよい問いかけを見つけるための手段は様々なコンテキストに基づく考え方を取り入れる他になく、そのためにはより様々なバックグラウンドを持つ人がデータを通して観察を行えるとより良いというわけです。これがより組織内で広範囲に展開できるとレバレッジが効くようになります。
データ基盤開発における文化的実現におけるトピックは この「プロダクトをよくする」という共通の目的をもとに、バックグラウンドやコンテキストが異なる複数の観点をいかに統合できるかにあるように見えます。 そしてこの課題へのアプローチは、ヒトとヒト、ヒトとモノといった ヒトを中心とした有機的な枠組みをシステムに落とし込むことで図られます。 これはまさにアーキテクチャ(デザイン)に対する問いかけです。
Rettyにおけるデータウェアハウジング
弊社ではBigQueryを中心としたデータウェアハウシングを行なっていますが データ基盤開発をすすめるにあたり、その中心にはデータエンジニアではなくデータアナリストを据えるようにしています。 データ基盤開発の方向性も含めてどのような機能を実現していくべきかは ドメイン実践者が担っていけることが最も効果的ですがその実践者はデータアナリストだからです。
データエンジニアの役割は自転車に乗るための補助輪のような役割で アナリストが中心的にデータ基盤上の開発を担っていくためには、コアとなるコンセプトやアーキテクチャの整備、最低限のデータの整備、標準化に向けたツール整備と普及活動がメインになります。
データ基盤開発の標準化
データアナリストが主体的なデータ基盤開発を担えるようになると同期コストは低くなり、個々で動ける範囲が広くなる傾向にあります。 しかしながら、個々の自由度を高めすぎると起こる問題として データ基盤開発全体としての一貫性や整合性が失われカオスを生み出すことになります。
データ基盤の開発は元々依存関係が多層かつ複雑になりやすいものですがこういった形でもたらされるカオスは開発可能性の著しい低下を招きます。 不安定なデータソース、定義が個人で揺れる指標系、自明ではない謎の条件のフィルタといった カオスによりもたらされる悩みのタネにはいとまがありません。
標準化は個々の不規則とも言える動きに一定の制約をあたえ、全体としての秩序を生み出すための動きです。 管理統制のためのルールを作り、動きを縛るためのものではなく 標準の上に乗っかることで恩恵が受けられる、創造性をもたらす不自由さが理想的です。
標準化というと中長期的効果があげられることもありますが 簡潔な枠組みを提供することができれば、学習コストを低くする効果もあるため短期的効果も期待ができます。
Rettyで導入している標準化としては次のような動きを標準化のために取り入れています。
SQLにおける自動テストの取り組みについては 別記事としてまとめてあるので参照してください。 paper.dropbox.com
効果的なプラクティスの導入
標準を定めるだけではなく実践的に導入し、アナリストたちが主体的に取り組めるように 促していく動きも必要になります。
データウェアハウシングを積極的に進める初期フェーズにおいては PRのコードレビューを通しての教育または標準へのフィードバックを通して 洗練化に努めました。 SQLを通した自動テストのプラクティス は、アナリストにとっては元々馴染みの深いものではないですし テストの考え方は、アプリケーション開発とは異なるテスト戦略を考える必要がありました。 アナリストたちが主体的に取り組むことを目指して、モブプロといった開発形態をとることも効果的な手立てでした。
ピーク時と比べ主要な開発が落ち着いた現在でも 月に一回程度アナリストを集めての同期的に課題解決のための集中開発日を設けることで データ基盤の持続的開発に取り組んでいます。
これらの1年のより詳しい取り組みについては平野の次の記事も紹介しているので ぜひご覧くださいしてください。
データウェアハウシングのための実践的なレイヤ構成
この記事の残りはRettyで導入したプラクティス の紹介として データウェアハウシングを進めるにあたってのアーキテクチャを紹介したいと思います。
Rettyでは、データウェアハウシングの次の図のようなレイヤ構成をとっています。 これらのレイヤがデータウェアハウシングにおいてどのような役割を持つかについて紹介していきます。
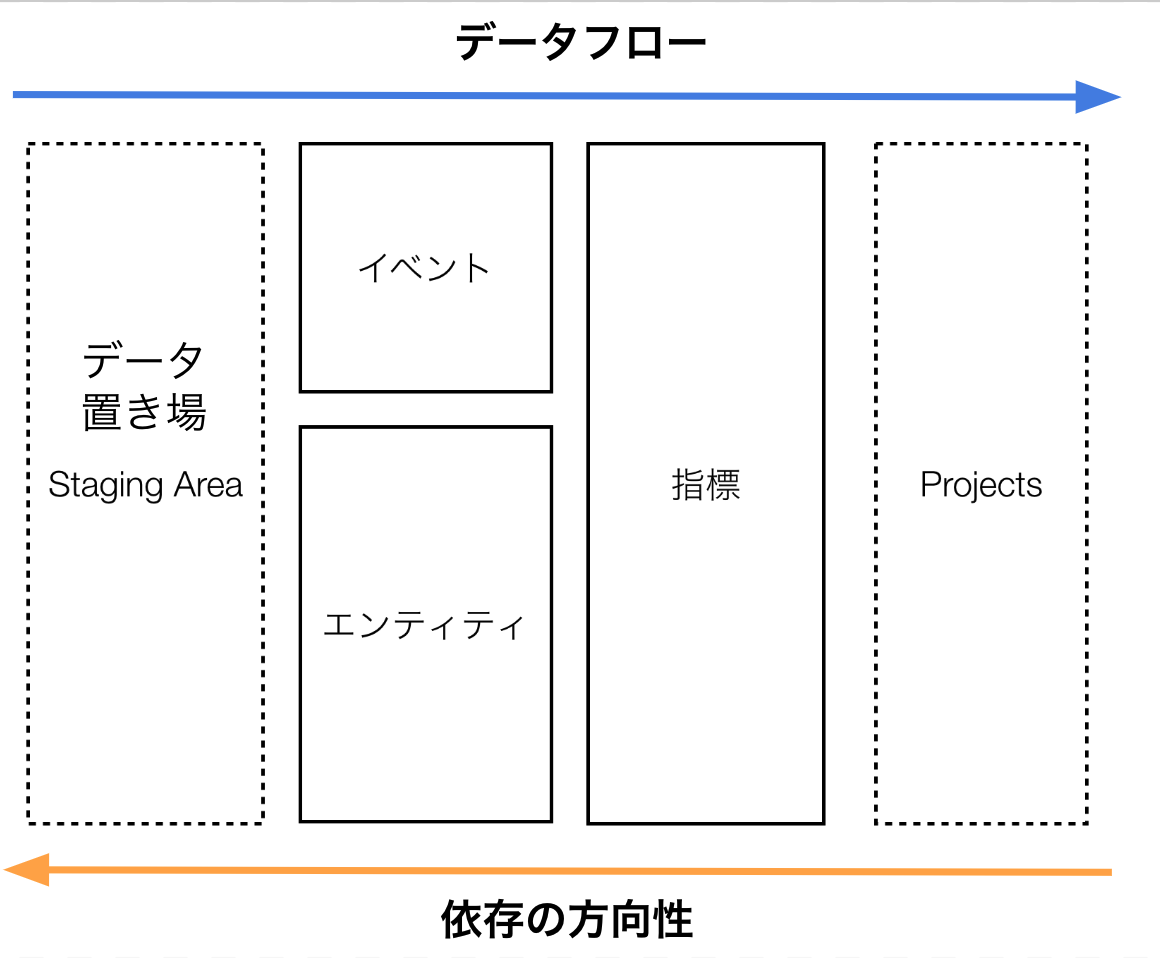
データ置き場 (Staging Area)
Rettyにおけるデータパイプラインでは その基本コンセプトとしてETLではなく、加工処理(Transform)を遅延させるELTを採用しています。
ELTでは、必要最低限の加工(仮名化やマスキング、スキーマのための構造化)に抑えた状態で データを配置します。 データの置き場(Staging Area)はそのための場所です。
似た役割を持つデータレイクとの違いは、
- データ置き場のデータBigQueryに格納できるだけの構造化がされていること。
- BigQueryで利用可能なソースとして公開されるため多少不便ではあるが誰でも利用可能
といった点にあり想定するユースケースが異なります。
これらはBigQuery上の単一のデータセットに様々なテーブルを格納する形で実現しています。
RDSのマスタにはm_, イベントデータではl_といったようにデータソースごとに接頭辞を分けて整理しています。
プロジェクト (Projects)
データフロー上もっとも下流となる位置に配置されるプロジェクト(図中のProjects)は プロジェクトそれぞれのユースケースに応じて利用されるデータセットです。
ひとつBigQueryのデータセットを割り当て、データアプリケーションの実データやチームのダッシュボードを含めて、利用方法は各プロジェクトの担当者に一任しています。
一方で、敷いているルールとしては
各プロジェクトでは依存関係を明確にするためにDWH内のテーブルを参照するだけのビュー(i.e.
select * from [table名] )を設置してもらっています。
これはデータ基盤全体での依存の管理と上流側の影響により下流であるプロジェトに問題する場合の開発可能性を保持するためです。
イベント層
データ置き場(Staging Area)に置かれたデータはBigQueryへ格納のための最低限の構造化はされていますが、データ利用の観点では使いやすくはない状態で配置されます。
データ置き場にあるイベントデータの変形を行い、より利用がしやすい構造化された状態で保持するのが、イベント層の役割です。 整形の仕方によっては個々のテーブルの独立性を維持しつつ、ひとつのデータソースが複数データソースで利用されることもあれば、複数のソースがひとつにまとまることもあります。
RettyではAndroidやiOSのネイティブアプリとWebまたはグローバル展開という形で 様々なプラットフォームで展開していますが クロスプラットフォームな分析利用がしやすいように、構造を共通化するのもイベント層の役割です。
イベント層のビューにはテストを記述することができますが 加工操作のテストだけでなくデータソースに関するテストも行うことで データソースの異常にも気付く仕組みを簡単ながら作ることができます。
エンティティ層
エンティティ層は、プロダクトの対象ドメインにおける 主要な実態となるエンティティを取り扱うためのレイヤです。 スノーフレークスキーマ*1におけるディメンジョンテーブル群に相当します。
ひとつのエンティティにひとつのデータセットを割り当てるように配置しています。
データセットをひとつ割り振ることでアクセス制御等が行いやすくなります。
具体例を出すと、エンティティユーザ に関する情報を取り扱うためのデータセットent__userは次のようなテーブル群から構成されます。
ent__user ├── core 基本利用されるテーブル ├── dim__activity dim__xxxx の命名はIDに対するセグメントを与える └── history: ent__user.coreに関する履歴を管理する (自動生成)
エンティティ層を開発するにあたり、データソースはRDSなどのテーブルが対象になることが多いですが
RDSのテーブルは通常アプリケーションのための正規化がされています。
エンティティそうではこれらの非正規化を行い、エンティティに対する属性情報がひとつのテーブルにまとまるようにします。
(ent__user.core)
非正規化された情報とは別に、分析観点で提供するセグメントの提供することはよくあるユースケースです。
ユーザに対するセグメントであれば、サービスの利用頻度などを基準として分析を行うことは珍しくないでしょう。(図中のent__user.dim__activity)
エンティティ層の各データセットには、それぞれのエンティティに対するセグメントを取り扱うためのテーブルもまとめるようにしています。
このようにすることで、対象のエンティティに関する分析がどのように行われるか?といった知識の把握に努めやすくなります。
エンティティのデータセットごとに、自動的に履歴テーブル(図中のent__user.history)が用意されます。
通常アプリケーションのデータベース上のテーブルは、as-was分析用途に耐えうるものではありません。
そういった観点をデータウェアハウス上のでエンティティで保証するようにしています。
実際には、そのエンティティインスタンスレベルでの属性とその値の変化を
自動的に縦持ちに変換するクエリを生成し、定期ジョブとして履歴を自動的に保持するようにしています。
個々のエンティティの関係の取り扱いは、プロダクト開発のデータモデリングと密接に紐づけられます。
次の図は、Rettyにおける概念モデリングの資料の一部を切り出したものです。
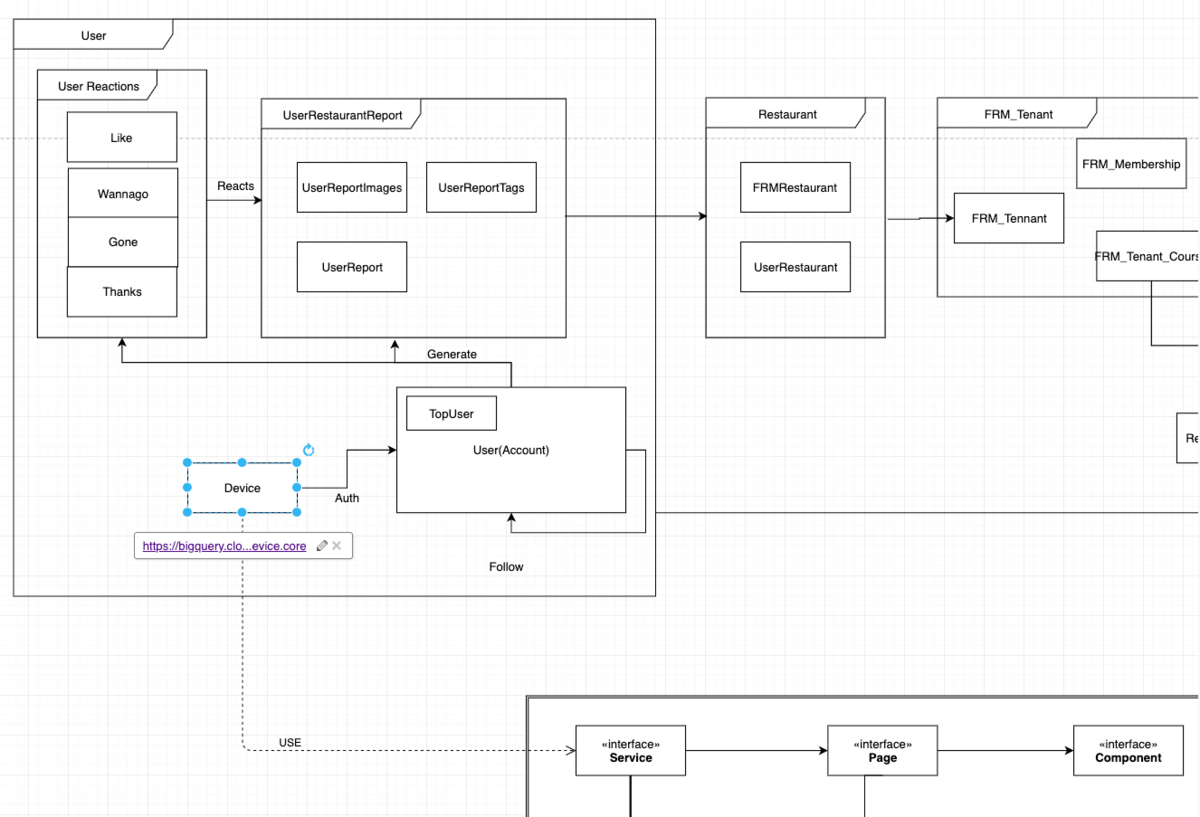
データの分析利用の際には、このような知識が必要となることも多くあります。 対応するデータセットのリンクをドキュメントを埋め込むなどのより利用に即した形式 工夫を凝らしています。
指標層
最後に指標層は、分析を目的とした集計作業を取り扱うためのレイヤです。 スノーフレークスキーマでいうところのファクトテーブルに相当します。
指標データセットの役割を持ちます。
- 指標に関する集計レコードの最小粒度(グレイン)の定義
- 計算方法の定義
指標層では1つ以上の指標を指標グループにまとめデータセットを割り当てます。 データセット中にはユースケースに応じた様々なテーブルが配置しますが 指標データセット中の全てのテーブルは同じ指標グループをスキーマにいれる取り決めとしています。
アプリケーションに関する分析でもっとも基礎的な集計であるページビューの集計を具体例に挙げ説明していきます。
アプリケーションのページビューイベントに関する、指標データセットとして
metric__pageview を用意しようと考えたとき、次のようなテーブルから構成されます。
metric_pageivew ├── __core 集計の最小粒度と計算方法を定めるためのテーブル ├── __time__search _coreを利用し、searchに特化した集計 ├── time__search__daily__past__7days よく利用される集計期間について__time__searchから生成されるビュー (自動生成) └── history: 集計の履歴を管理する (自動生成)
データセット内の指標に関する集計レコードの最小粒度(グレイン)の定義および指標の集計方法は、__coreが慣習的に担っています。
metric_pageivew._core.は例えば次のようなスキーマを持ちます。
time_id :時間エンティティのID
page_id :アプリケーションページエンティティのID
user_id :利用者エンティティのID
metric {
n_event :イベント数
hll_session : ユニークセッション数(Hyperloglogスケッチ)
hll_user : ユニークユーザ数(Hyperloglogスケッチ)
}
metric_pageiew内に配置されるテーブルは
metric {
n_event :イベント数
hll_session : ユニークセッション数(Hyperloglogスケッチ)
hll_user : ユニークユーザ数(Hyperloglogスケッチ)
}
の指標を持つことが期待します ページビューという指標では、単純な数え上げのイベント数だけでなく、ユニークユーザ数やユニークセッション数も一緒に計算しています。 これらは別々で管理されるよりも集約されていることの方が望ましいためです。
最小粒度の定義することができれば、任意のディメンジョンに対する集計はエンティティに対する周辺化により再集計を行うことで導くことができます。 timesearchをはじめとするユースケースに応じたテーブルは、__coreから不要なエンティティの周辺化を行い列削除することで得ることができます。
as-was分析のため指標に対する履歴テーブルも自動で生成されるようにしています。 どのような指標を定義するか、はデータアナリストの主要な開発物のひとつであり プロジェクトのコンテキストにより更新変更されることがとりわけ多く発生します。 指標定義の一元化と指標定義のコードを変更した場合には、変更履歴テーブルを利用し自動的に数値比較を可能にするような仕組みを提供することで開発をしやすくしています。
まとめ: 知識のコード化 (Knowledge as Code) を目指して
Rettyにおけるデータ基盤についてのレイヤ構成について紹介しました。
Rettyで目指しているデータ基盤開発のゴールは「知識のコード化 (Knowledge as Code) 」を持続可能な状態にすることにあると考えています。 知識のコード化とは、実践的なドメイン知識を再利用可能な実装の形で提供可能にすることを指します。 一番のドメイン実践者であるデータアナリストが培った知識を再利用可能なものとして データ基盤に継続的に反映することが最も好ましいでしょう。
今回紹介したレイヤ構成では
- エンティティをどの単位で区切るか?
- どのような指標層のデータセットを用意するか?
といった点において、まだまだ設計をつめていく余地があります。
プロダクトの変化に合わせて、リファクタリング等を通して データ基盤の洗練も行っていきたい所存です。
本日紹介した内容が、データ基盤開発に取り組まれているみなさまの参考になれば幸いです。