
はじめに
データアナリストとして今年中途入社した上野(@hiro_30_1000)です。
本日より、Retty分析チームの連載「#dbtでデータの民主化」を始めます!
この連載では、Rettyのデータアナリストが約3ヶ月間取り組んできた「dbtの導入」を中心テーマとし、
その仕事の裏側、プロセスを公開していきます。
「#dbtでデータの民主化」の公開スケジュール
本日から3週間に渡り、週1回ペースで記事を公開予定です。
- 9/14(水):データアナリストがdbtを使って育てるデータマネジメント
- 9/22(木):dbt移行プロジェクトを振り返ってみた
- 9/29(木):DWHの管理を内製ツールからdbtに移行した話
本記事では、データアナリストがdbtを用いてデータマネジメントをすることで実感したメリットを中心に共有したいと思います。
また、具体的なdbt導入のプロジェクト進行プロセスは、新卒のアナリストメンバーがPJ進行をしてくれたので、そこで詳細をお話させて頂きます。
誰に読んでほしいか
- データパイプラインは一定作っている or 開発中 or 改善中の方々
- dbt導入を検討しているが、まだメリットが腑に落ちていない方々
- アナリストだけでどこまでデータマネジメントできるのか興味がある方々
- データマネジメントをするメンバーの採用がボトルネックになっている方々
TL;DR
- これまでは、CI/CDを用いたDWH管理体制を「内製」ツールを作って運用していましたが、作成者が既に退職済みで内製ツールが止まった場合の復旧にかなりの工数が掛かる等ブラックボックス状態であった
- dbt導入のゴールは「内製のDWHのCI/CDツールからの脱却による開発効率の向上」とし、データアナリストが中心に内製ツールからdbtへの移行PJを進行、モデル開発を進め、約3ヶ月間掛けて移行を完了させた
- Rettyでは分析の民主化(過去記事)をしているので、dbt活用メリットの1つである依存関係が可視化されることで、データを扱うメンバーが各自で意味が把握できる体制になり、民主化にレバレッジが掛かる土台ができた
- データ基盤がモダンになったことで業務委託メンバーがday1からデータマネジメントで活躍できるようになった
- データ基盤に対する理解が社内で進むきっかけにはなった。今後は「DWH開発の民主化」も挑戦していきたい
導入背景(課題)

前提
- Rettyの分析基盤(BigQuery)は、データレイク層/データウェアハウス層(ex/ ent層,kpi層)/データマート層の3層構造で構築されている(過去記事)
- データレイク層→データウェアハウス層までは分析チームで品質管理、データマート層は利用者が管理している
- Lookerはデータウェアハウス層からのみ接続とすることで、オレオレダッシュボードは作成されにくいようにしている
- 開発やテスト、デプロイ等を内製ツールを利用して行っていた

1/ 内製ツールの不具合が多く、復旧に時間が掛かる
これまでは、CI/CDを用いたデータウェアハウスの管理体制を内製ツールを作って運用していました。
また、その作成者やソースコードを熟知しているメンバーが既に退職済みで、メンテナンスが十分されていない状況でした。
結果、内製ツールが止まった場合の復旧に工数が掛かる等ブラックボックス状態でした。
2/ 分析基盤内に問題が起きた際、原因特定に時間が掛かる
- ①元々のテーブル量が多い(ex/ アプリ、Web、お店側、ユーザーさん側)
- ②2020年から「分析の民主化」を行っており、プロダクト部門やセールス部門等が自らクエリを書いてデータ抽出や分析を進めたり(BigQuery利用者:社内の約60%)と分析需要の拡大によって、必要なディメンションテーブルが増えていた
上記①②によって依存関係の全て頭にいれるのは困難な状態でした。
また、依存関係を把握しやすくするための可視化ツールなどもありませんでした。
結果、
- 「今日のユーザーのネット予約周りの数値が更新されてなさそう」
- 「KPIの数値がおかしそう。多分Webとアプリが同じ数値になってるから、どっちかがおかしいと思う」
- 「月初に更新される獲得周りのデータが何かおかしそう」
など何か起きて各部門から連絡をもらった際、分析基盤内*1の問題を把握するにはクエリを読んで辿るしか方法がなく、原因特定に時間が掛かり、日々の分析業務(意思決定支援)の進行が遅れる形で徐々に課題が顕在化していきました。
3/ データマネジメント職種の採用高度化
Rettyでは既にデータパイプラインは構築済みですが、事業のフェーズが変わるにつれてデータ基盤の運用・アップデートしていく際にアナリティクスエンジニアを採用し、組織立てていくことが非常にハードルが高いという課題がありました(市場全体として難易度が高いかと思います)。
また、データパイプラインの大本のアップデートとなると、一定のエンジニアリング知識が必要なので、社内の別チームにせざるを得ないですが、社内でもリソースの確保が難しいという状況でした。
そこで、dbtを導入をすることで「内製のDWHのCI/CDツールからの脱却による開発効率の向上」を目標とし、アナリストが中心に内製ツールからdbtへの移行を進めることにしました。
dbtとは(簡単に)
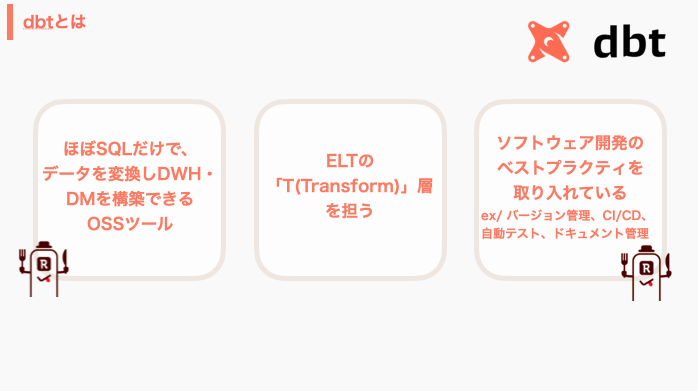
こちらは、色々なところでまとめれているので簡単に記載します。
- dbtの正式名称はdata build tool
- dbtはELTデータパイプラインの「T(Transform)」層の部分を担います。既にデータウェアハウスに読み込まれたデータを変換することに優れています
- SQL(のSELECT文)を知っていればデータパイプラインを開発できます
- テンプレート言語のJinjaが組み込まれているので、SQLだけでは難しい処理(ex/ for文)をプログラム的に処理できます
- また、Rettyではdbt cloudも活用しており、その機能により「ソフトウェア開発のベストプラクティス」の恩恵を受けられます。具体的には、バージョン管理、CI/CD、自動テスト、ドキュメント管理をサポートありでデータパイプラインを構築できます
導入して感じたメリット

大きく3つあります。
1/ アナリスト自身でデータの品質を担保しながら開発できる体制づくり
個人的に大きなポイントは、上記で記載した「ソフトウェア開発のベストプラクティス」を取り入れているところにメリットを感じています。
クエリをGitでバージョン管理し、PRが通ったものだけがデプロイできるCI/CDの環境を構築できたり、内蔵されている自動テスト等、ソフトウェア開発で当たり前のように行われている手法を、データ変換の世界に取り入れてくれています。
例えば、テストをyamlで定義するだけで、指定したモデルのカラムにnullが含まれていないか、ユニークな値になっているかを簡単に書くことができます。(下記のように1行で書けます)
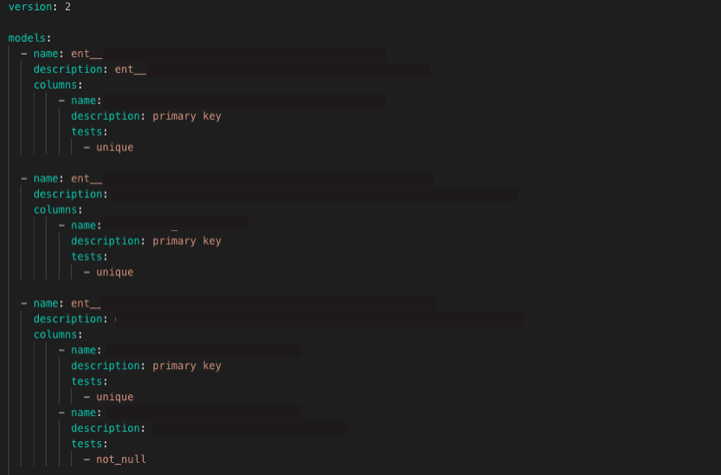
このようにアナリスト自身で自分たちがほしいテストをどんどんカジュアルに追加できます。 今まではテスト等を書くとなると、一定のエンジニアリング知識が必要でデータの品質を担保するのが難しい世界でしたが、アナリスト自身でもデータをカジュアルに作成・管理でき、 データの信頼性を作れるようになりました。
2/ 依存関係の可視化→分析の民主化にレバレッジが効く
前述の通りRettyでは分析の民主化をしており、BigQueryでクエリを書くPdMや営業企画のメンバーから複雑なテーブルのデータの依存関係や欠損について質問があった際は、データの構造を知っている古参メンバーやアナリティクスエンジニアに都度聞くしかありませんでした。
しかし、アナリストからでも伝えられるようになり、Linageによるテーブル間の依存関係が可視化できたりすることで、アナリスト以外のデータを扱う各メンバーでも、テーブルの意味が把握できる体制になり、民主化にレバレッジが掛かるような土台ができたと思っています。
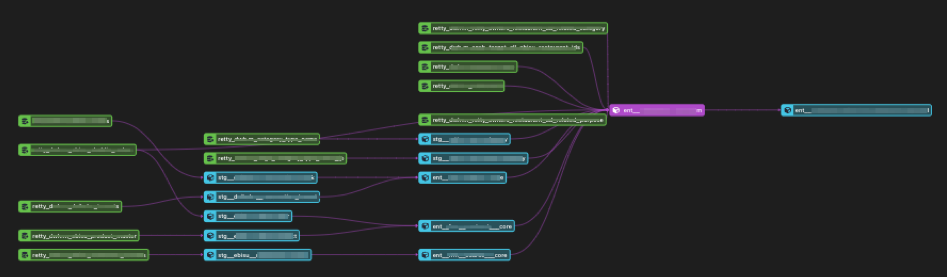
3/ 採用・オンボーディング視点
dbt導入でデータパイプラインの改善をSQLがベースのスキルセットでできるようになり、環境構築のハードルが下がったので、新しい人が入ってもSQLさえ把握していれば最初のPRを出すまでの時間が圧倒的に短くなりました。
実際に、新しく入ったデータマネジメントの業務委託メンバーがday1から基盤開発に関わることができています。
苦労
このようにdbtを導入する背景で苦労した部分もありました。
それは、意思決定支援をしながらdbtに移行するプロセスが同時並行し、リソースが圧迫した点です。
実際に移行プロセス当初は、dbtの移行と意思決定支援の優先度を決めておらず、特に移行完了期限も決めておりませんでした。
すると、各アナリストがスプリント(前提:アナリストもLeSSというスクラムで動いています。過去記事)の前半で意思決定支援の分析に時間を使い、最後ギリギリに余ったスプリントの最終日、最終日前日にdbt開発に着手、当時はdbt開発も慣れてはいなかったので見積もりより工数を使い、スプリントに間に合わないことが起きたり、dbtに対する知識に差がつきました。
工夫した点
この苦労した点を解決するために、「dbt移行PJ」とプロジェクトチームを発足し、優先度とゴールを明確にしました。
実際にPJ進行をしたメンバーは新卒1年目のアナリストメンバーを抜擢したり、朝会やPRレビュータイム、週に1回のdbt開発dayを設けたり、Wikiをつくり学んだことをドキュメントに書いたり、モヤモヤ解消やスキルの足並みを揃える工夫をしました。
具体的にどうやってプロジェクト進行したのか、進行の苦労した点等は実際に推進したメンバーから別途記事を記載するので乞うご期待ください!

最後に
「内製のDWHのCI/CDツールからの脱却による開発効率の向上」というプロジェクト目標が達成された今、当時目標を立てた時には見えていなかったメリットを多く享受できました。
メンバーのスキルアップという意味では、dbtを導入することでデータ変換・テストも書きやすく、実装コストが格段に下がったので、アナリストのデータマネジメントスキルをエンパワーメントするのに凄く役立ったと思います。
また、社内でのデータマネジメントの浸透という意味でも大いに役立ちました。
データ基盤のメンテナンスが行き届かなくなると数値がずれたり、ダッシュボードが壊れたり、事業判断・経営判断に中長期の影響が出ます。このメンテナンスがいかに大事か、dbtを導入するプロセスで社内で広報活動も行い、データ基盤に対する理解が進むきっかけにもなりました。
次のステップとしては、「分析の民主化」だけでなく「DWH開発の民主化」も挑戦していきたいです。開発の敷居が下がったので、データ抽出・分析を行うPdMや事業サイドのメンバーもDWH開発に携われればと考えています。
といっても、現時点ではまだまだハードルが高い部分はあるので、dbt開発のオンボーディング体制を整えていったり、デプロイされたモデルに紐づくドキュメントをホスティングできる機能を使ってデータ分析チーム以外のメンバーにも共有する等、データ活用のレベルを上げる工夫はいくつかできるかと思います。
このようにRettyのデータアナリストは分析以外にも様々な方面で社内のデータ活用の底上げ・民主化を進めているので、少しでも興味を持って頂いた方、具体的な話を聞いてみたいと思った方は気軽にお話しましょう!
参考
*1:ここでいうデータ分析基盤はBigQueryを指します。データ転送基盤はAirflowになります。