この記事は Retty Part1 Advent Calendar 2021 の5日目の記事です。
はじめに
アナリティクスエンジニアの渡邉です。毎年多くのアップデートを記事にしているRettyデータ分析チームが、今年に取り組んだことの一つがLookerの導入です。この記事では、Looker導入のプロジェクトの道程と、導入時にして効果的だった取り組みについてご共有したいと思います。
要約すると下記の通りです。
- Rettyは「データの民主化」を掲げていたが、データ出しのツールがBigQueryとDataPortalだけで利用障壁が高かった。
- Looker導入は「BigQueryに慣れない層がLookerを用いて、自らダッシュボードから分析を広げられる状態」を目標にした。
- プロジェクト完了後には、データ出し業務はデータアナリストから離れ始め、新たにLookerを用いてデータ活用を始めるチームも生まれた。
お時間がある方は、ぜひ最後まで読んでくだると嬉しいです。
なぜLooker導入に至ったのか
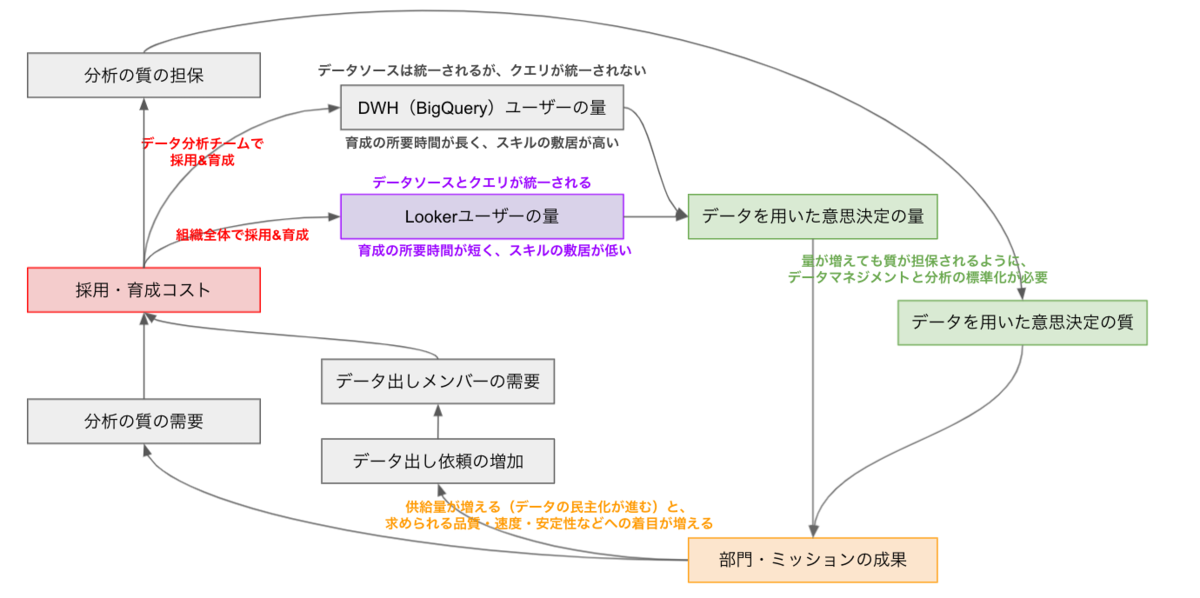
まず「なぜLooker導入に至ったのか?」という点についてお答えします。Rettyにおいては「データアナリストの役割が攻めから守りまで増えすぎた」からでした。下記の通り2018年から2021年をかけて、データアナリストの役割は増え続けました。
2018年初頭頃からチーム体制になり、今日まで続くデータの民主化を掲げた ・ 定量的な取り組みへの関心が高いチームもしくはメンバーに並走するスタイル ・ データアナリストが、データ出しからダッシュボード作成まで全て対応していた 2019年頃には、BigQuery上にDWHが誕生し、ガバナンスの効いたデータ出しが可能になった ・ ほぼ同時期にBigQuery Expertというデータ出し習熟者を育成する取り組みが始まった ・ 定量的な取り組みへの関心が高いチームもしくはメンバーが自らデータ出しできる状態 ・ このときデータアナリストの役割は、データ管理もしくは分析の高度化のどちらかが色濃くなった 2020年頃からは、”Data Driven”から”Data Informed”への転換が進んだ ・ データという過去情報から現在を認識しづらいご時世になったため? ・ そのなかでデータアナリストはユーザーリサーチという新たな調査手段を得ました ・ 定量データとユーザーリサーチを併用し、ユーザー像をより高い解像度で捉えことができるようになった 2021年頃からは、データアナリストの役割過多を解消する標準化の試みが進んだ ・ 依然としてBigQueryに慣れない層からのデータ出しなどの依頼が続いた ・ この3年間を経て、データアナリストが求められる役割が攻めから守りまで増え続けた
もちろん役割過多の解消のために、新たなデータアナリストの育成や採用も解決策になりますが、解決までの不確実性とリードタイムが懸念点でした。そこで別案として新たにLookerを導入をすることで、"BigQuery Expert"を通じて既にお任せできていた「データ出しからダッシュボード作成まで」の役割を、BigQueryに慣れないメンバーにもお任せしようと考えました。
Looker導入プロジェクト
ここからはLooker導入プロジェクトの全体像と各フェーズでの動きを共有します。
プロジェクトの全体像
プロジェクト目標は「BigQueryに慣れない層がLookerを用いて、自らダッシュボードから分析を広げられる状態」でした。
この目標の第一の意図は、顧客志向を忘れないことです。Lookerは社内メンバーが主な顧客になるITサービスです。今回とくにLookerを利用して欲しいメンバーを目標の主語におき、彼らが継続利用したくなるサービスにする軸がブレないようにしました。また第二の意図は、DWHを利用したダッシュボードへの移行です。今後お任せする「データ出しからダッシュボード作成まで」に必要な実装の基ができるだけでなく、DWHを利用していないダッシュボードの廃止を進めていく狙いもありました。
プロジェクト計画は、導入・浸透・運用という3種のフェーズに分け、分析チームのLookML開発進捗と、導入対象のチームに提供できる有用性を約束しながら進めました。またアナリティクスエンジニアが1名、データアナリストが5名のメンバー構成です。データアナリストが各チームのダッシュボード移行とBigQueryに慣れない層へのヒアリングを担い、アナリティクスエンジニアはデータアナリストが能動的にプロジェクトに取り組むためのその他諸々を担いました。

Looker導入フェーズ
そして始まった第一のLooker導入フェーズでは「Lookerの実用が期待できる状態」を約束しました。まずLookerが組織全体(とくに決済権を持つ層)に期待されることが重要と考えつつ、その裏ではLookerを運用可能な状態にするための土台作りを行いました。
①組織全体(とくに決済権を持つ層)に期待されるために
なぜ組織全体(とくに決済権を持つ層)に期待される必要があるかというと、現場からボトムアップ型にLooker導入による改善の期待を強めるだけでなく、トップダウン型にLookerのライセンス割当や追加契約にも納得してもらうためでした。改善の貢献確度の高いチームからLooker導入を始め、将来的なライセンス追加の意思決定をスムーズにするための仕込みです。
この仕込みのために、継続的な進捗共有とハンズオンは欠かせない活動でした。ボトムアップ型で期待を得るために、スプリントレビューにお邪魔して、導入が進んだLookerの機能を動かしながら説明し、どのような用途で期待ができそうかの意見収集をしました。またトップダウン型で期待を得るために、KPI進捗共有のMTGにお邪魔して、同じくLookerを動かしながら説明して意見収集を行いました。その場でスケジュール配信まで設定したり、ドリルダウンを用いた深堀分析の実演はとくに好評価でした。
この活動を続けつつ、各現場におけるLooker導入の費用対効果も同時に測りました。この活動をデータアナリストが担うことで、日々連携しているチームの現状やその後についての確かな情報をもとに判断できました。費用対効果の計算の一例として、「データ出しからダッシュボード作成まで」をLookerを使わずに実行できる人材の時給へと換算し、依頼遂行の月間の累積時間を掛け合わせることで、Lookerを導入することのメリットを算出しました。
②Lookerを運用可能な状態にするために
データ分析基盤のアーキテクチャ設計だけでなく、安定して開発タスクに取り組める工夫もしました。
データ分析基盤のアーキテクチャ設計において更新はほぼありませんでした。BigQueryでできる「データ出しからダッシュボード作成まで」の体験をLookerでも可能にする方針のため、BigQuery上にDWHとセマンティックの管理の責務を持たせることを継続し、LookerにはフロントエンドやBFFのような責務を持たせました。(DWHとセマンティックの管理ツールは、ここ最近の進化が目覚ましくてワクワクします)またLookerでのデータセキュリティ管理の責務を減らすために、GoogleOAuthを用いたユーザー別のBigQuery認証を用いることで、BigQueryとGoogleWorkspaceの権限を透過的にLookerで適用できる状態にしています。
安定して開発タスクに取り組める工夫として、「データ出しからダッシュボード作成まで」の業務プロセスのなかに、DWHとLookMLの開発を含むように変更しました。以前からデータアナリストもDWH開発をする方針でしたが、データアナリストにとってDWH開発タスクの優先度を上げることが厳しく、開発運用が追いつかない問題を起こしていました。LookMLの開発も同じく状態になる恐れがありました。そこでデータアナリストの効果検証や予実管理の業務プロセスに含めて、自ずとDWHやLookMLの開発タスクが着手されるようにしました。もちろん業務プロセスが増えるためリードタイムが長くなる懸念がはありますが、一度対応すればデータアナリストが関与せずとも再利用可能なデータ出しができるメリットが分かりやすく、データ分析チーム内外からの合意を得やすかったです。
(詳しくは下記の登壇スライドに記載しています)
Looker浸透フェーズ
Looker浸透フェーズでは「BigQueryに慣れない層がLookerを用いて、自らダッシュボードから分析を広げられる状態」が約束されました。導入フェーズに見積もられた費用対効果などの情報を参考に優先順位をつけて、データアナリスト主導で既存ダッシュボードをLookerに移行してもらいつつ、その裏で自分はLookerが継続利用されるために必要なその他のことに着手していました。
①データアナリスト主導のダッシュボード移行のために
データアナリストへのモブプロを通じて、データモデリングの思考法を身につけて貰い、DesignDocにナレッジとノウハウを貯めていきました。
データモデルを意識しながらダッシュボードを整理する思考は、普段のデータアナリストの業務に必要がないためどうしても不慣れです。またデータアナリストが慣れ親しんでいる分析クエリ作成の思考だと、限定的なコンテキストに則したセマンティックレイヤーを、DWHのエンティティに混在させてしまう恐れがあります。そのためモブプロ形式をとることで、データモデリングの観点からのフィードバックを加えて思考法を身につけてもらいつつ、また頻出する誤解の解消のために、DWHのDesignDocにナレッジとノウハウを貯めていきました。
実際のダッシュボード移行作業では、DWHを利用していないダッシュボードの整理は難しく、データモデルに紐解く作業だけでは済みませんでした。未知のデータソースの管理者探しや、ダッシュボードごとに数値が異なる同名フィールドの言語定義探しには、想像よりも多くの時間を費やしました。とても悩ましい作業でしたが、これらのズレが組織内で存在していたことがデータアナリストとダッシュボード運用者の間で共有される機会になり、定義の揃ったデータ分析環境の利用を推進していくべきという考えが組織的により強くなりました。
②Lookerが継続利用されるためのその他
Lookerユーザーの育成フローを構築し、データ分析チームのオフィスアワーを始めました。
Lookerユーザーの育成フロー構築においては、Lookerユーザーが次のユーザーを育てられるトレーニング資料を用意しました。いらすとやさんのイラストを拝借したポップな雰囲気の資料で、中身はLookerについての簡単な解説と、データ集計の考え方からexploreの使い方までを体験できる例題が載っています。データ集計をdimensionのmetricのパズルだと捉えて貰い、あとはexploreでパズルのピースを選ぶように操作するだけだと学んでもらう内容です。また資料の中にDWH(BigQuery)とLookerの関係性についての解説が含まれているため、LookerユーザーからDWH(BigQuery)ユーザーへと円滑にスキルアップできるような工夫もしています。
そしてデータ分析チームのオフィスアワーは、顧客志向を継続するためのユーザーヒアリングの取り組みです。今回のLooker導入により「データ出しからダッシュボード作成まで」を任されたBigQueryに慣れない層の方々は、BigQueryに慣れる層よりもデータ集計や数値指標に難しさと不安を感じることが想定されました。そのため彼らが「何が分からないのか分からない」状態から初めても安心でき、ラフに参加してくれれば解決までの糸口が見つかるような場が必要だと考えて、オフィスアワーの取り組みを始めました。想定通りオフィスアワーでは色々な意見・質問・雑談が寄せられており、データ分析基盤の全般の改善に繋がっています。またLookerの継続利用者が積み上がり続けていることからも、きちんと効果を発揮してくれているのではと思います。

最後に
以上のような道程を経て、Rettyでは今Looker運用フェーズへと進捗しています。
無事プロジェクト目標が達成されたいま、プロジェクト背景であった「データ出しからダッシュボード作成まで」の依頼が実際に減り始めただけではなく、今までデータ活用ができていなかった、BigQueryに慣れない層が多く属するチームからLooker導入依頼がくるようになりました。この依頼が来たときに、データの民主化が組織全体に行きわたる土台ができたことを実感しました。
データの民主化の達成見込みがたった今、データ分析チームでは「データマネジメント」と「高度な定量・定性分析」の需要が急速に高まっています。これらの領域のお仕事について気になる方は、下記のリンクからご連絡ください。お待ちしております。