
こんにちはRettyの二見です。9/5にRettyでData Platform Meetup #1を開催しましたので、イベントレポを考察を兼ねて書きたいと思います!
Data Platform Meetupは、自社のデータプラットフォームを設計/開発/利用している方がノウハウを発表したりカジュアルに情報交換できるイベントです。
発表者は
Retty 竹野 @takegue
yuzutas0さん @yuzutas0
エウレカ 鉄本さん @tamaki0506
メルカリ 石田さん @shoei
と各社から豪華な方々に来ていただきました!
100名の募集に対して200名近くの応募があり、大盛り上がりのイベントとなりました。
- カルチャーとエンジニアリングを繋ぐデータプラットフォーム(Retty:竹野)
- データレイク構築後の四方山話(yuzutas0さん)
- DataPlatform構築プロジェクト推進の事例と学び(エウレカ:鉄本さん)
- 大規模サービス開発における分析用データの必要要件(メルカリ:石田さん)
- Data Platform Meetup#1 の考察
- おわりに
カルチャーとエンジニアリングを繋ぐデータプラットフォーム(Retty:竹野)
https://speakerdeck.com/tkngue/karutiyatoenziniaringuwotunagu-detapuratutohuomuspeakerdeck.com
トップバッターは弊社の竹野からの発表で、データプラットフォームがデータに付加価値を与える上でどのような役割を果たしていて、弊社でどのように作り込んでいるのかが発表されました。

(竹野)「Rettyでは価値のデリバリを大切にしている。データからUser Happyを生み出すためにデータプラットフォームを構築している。ナレッジを持つ人がプラットフォームにコミットすることでサイロ化を防いでいる」
Rettyのここ数年でのSQLのクエリ数は約4,000から約46,000に増えており、量から質を高めていくフェーズになってきました。
その中で「価値のデリバリ」を大切にしており、価値を定義するカルチャーとエンジニアリングの水準を揃えて設計していくことが大切だと言います。
具体的にRettyでは、データプラットフォームを分析者にとってのプロダクトして定義しており、ドメイン知識を持った分析者がプラットフォーム開発にコミットすることで有益なデータプラットフォームを構築しています。
まとめ
— 岡部 翔太(Shota Okabe) (@shotaokb) 2019年9月5日
1.カルチャー(価値基準)とエンジニアリング(実現水準)をつなげる
→ヒト・モノ・コトのつなぎ目に価値が生まれる
2.ドメインを持つもの/人がプラットフォームの最前線で開発する
→安易な分割はしない
全線ですべての知識が集まるように交通整備を行う#DPM
データレイク構築後の四方山話(yuzutas0さん)
(yuzutas0さん)「データ基盤を1つのプロダクトとして扱う。現場に則していないと使われない中間テーブルが出来上がってしまう。十分な情報収拾とイシュー駆動の意思決定をしていくべき」
yuzutas0さんの発表は、データを疎通したあとどのように基盤を発展させていけば良いか悩んでいるデータアナリスト向けということで始まりました。
yuzutas0さんはデータプラットフォームを1つのプロダクトとして捉えており、現場の人が今どのようなイシューに直面しているかという点からデータ基盤を開発していくべきだと言います。

中間テーブルを作ったのに使われない場合は、データ利用者数と中間テーブル利用率を組み合わせた数値から重点を置いていくと良いと言います。
基本的にデータ利用者数はパレートの法則になりやすく、一部のデータがかなり使われている可能性が高いので優先度をつけやすいそうです(可視化のSQLはスライド内にあります)。
また不整合データはどこでクレンジングすべきかというトピックも印象的でした。
世の中の多い例としてはデータウェアハウスのETLでクレンジングするというものですが、yuzutas0さんの発表ではプロダクト側から改修を入れていくというものでした。
一回の相談や改修でデータレイク以前からの環境が整うのであればどんどんコミュニケーションをとっていくべきだと言います。
他にも「手順書は使われるなら最初のコストは払った方が良い」や「データ更新が遅い場合は処理時間が長いところを可視化してから解決する」など実用的な四方山話を話してくださいました。
DataPlatform構築プロジェクト推進の事例と学び(エウレカ:鉄本さん)
(鉄本さん)「スクラムでデータ基盤を開発していった。他チームを巻き込むことでニーズを引き出し、推進力とフィードバックが得られる状態にした」
3人目の発表者はPairsで知られるエウレカの鉄本さんの発表でした。
鉄本さんはデータプラットフォームを立ち上げる際の体験談としてどのような体制で開発を進めていったか、どんなしくじりをしたかを話してくださいました。

エウレカがデータ基盤を開発しているときに大切にしていることは以下の2つだと言います。
冪等性
プロダクトに影響を与えないようにすること
以上に関連するしくじり話として、テーブル分割の際にpartitiontimeを採用したら冪等性が担保できなくなってしまったことやtimestampが日本時間なのにUTCになってしまったことをあげていました。
また、最後にデータプラットフォームを開発する上で重要な点を以下にまとめていました。
- 負債覚悟で具現化すること
- 改修可能な組織体制にしておく
- 柔軟な組織変更はかなり効く
- 短期長期のデータ活用はチーム力で乗り越えるのが良さそう
エウレカでは鉄本さん自身がPOとなって、開発を推進していったそうです。
大規模サービス開発における分析用データの必要要件(メルカリ:石田さん)
(石田さん)「データ分析は、広い・重い・混沌の三重苦に陥りやすい。1,000人組織だとめちゃくちゃチームが多く、情報系統が入り乱れるので横一直線でデータを監視する組織体制やログ漏れの体制を築いてきた」
メルカリの石田さんからは、1,000人を超える規模のメルカリだからこその苦労話や効果的なオンボーディングの実例の発表がありました。
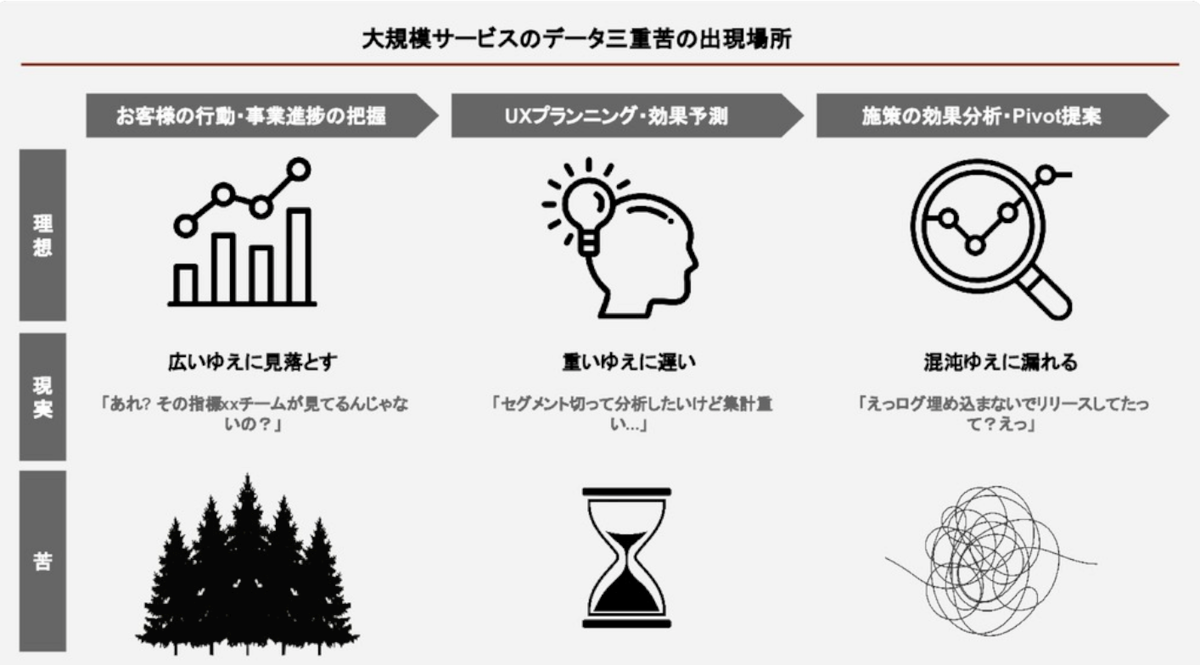
1,000人を超える規模だとチームが多くなり、ゆえに様々なデータや指標に関する苦しみが発生します。 メルカリのBIチームではそれぞれの苦しみに対して、大規模サービスでもデータを活用するための仕組みを用意しているそうです。
例えば、大規模な組織だと管理指標が増えていき、網羅的に管理するのが難しくなってきます。以前まで細かい指標やマイナー指標等のモニタリングは各チームの自主的な活動に委ねられており、明示的に網羅的に見る役割は存在していませんでした。
そこでアナリストチーム内に全体の指標を俯瞰するチーム・ダッシュボードを発足し、ビジネス上の異常を検知し、乗り越える体制を築いたそうです。
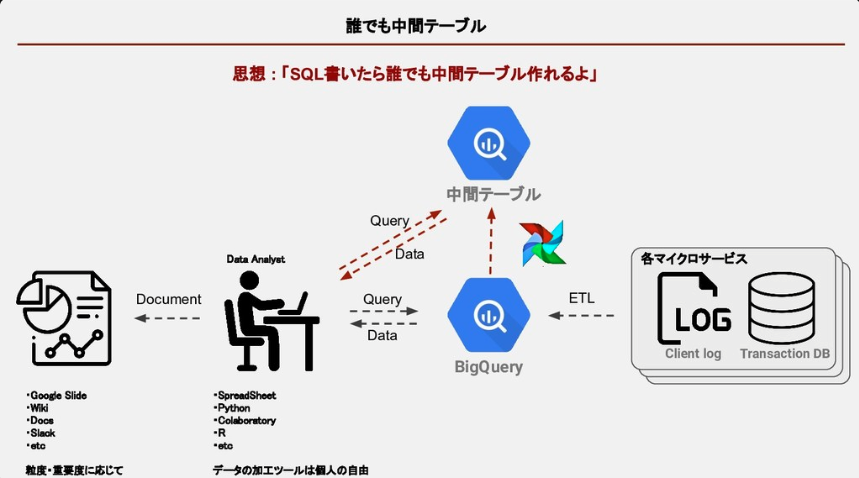
また、メルカリではBigQuery内に生ログが溜まっているので誰でも中間テーブルが作成できる環境であることや、Airflowのオンボーディングを作成し、誰でもデータ基盤(中間テーブル)を作れる環境を整えているようです。
Data Platform Meetup#1 の考察

今回のData Platform Meetupでは普段聞けないようなデータ基盤構築に関する様々な発表を聞くことができました。
各方々データ基盤に関する「カルチャー」・「実践的な活用方法」・「立ち上げ期の組織体制」・「運用フェーズとスケール方法」と異なる観点で発表されていた印象でした。
その中でもデータ基盤をプロダクトとして開発したり、POを置いて社内の人を巻き込んだりする話が印象的でした。
データ基盤という普段聞けないテーマながら、それぞれ共通点もあって学びの多いミートアップだった印象です。
おわりに
Data Platform Meetupは今回初めての取り組みでしたが、約100名という多くの方に来ていただきました。皆さん有難うございました。
データプラットフォームに関わる皆さんの発展の場となるべく第2回も開催したいと思います。
また、今回のイベントに参加したり、この記事を読んで「Rettyって面白そうだな」・「Rettyで働いている人にもっと具体的な話を聞いてみたいな」と思った方、ぜひ下記よりご連絡ください。
www.wantedly.com www.wantedly.com www.wantedly.com www.wantedly.com www.wantedly.com www.wantedly.com