この記事は、Retty Advent Calender 2020の20日目の記事です。 adventar.org 昨日は、ケイさんの2020年Rettyの新卒エンジニアのOnboardingでした。
はじめに
こんにちは、Retty株式会社広告コンテンツ部開発チームに2020年の4月からエンジニアとして所属している森田です。 好きな料理は、鶏肉料理(唐揚げや串焼きなど)です。 いよいよ2020年も残すところあと12日になりましたね!!
この記事では、私が2020年4月から開発に着手しているFood Data Platform(FDP)で普段取り扱っているRettyのデータ以外のクライアントから提供されたデータを汎用的に受け入れ可能にしたことについて話していきたいと思います。
FDPの概要
FDPは、食領域のビックデータ連携基盤システムのことです。

グルメサービスとしてのRettyの認知度は高く、ありがたいことに多くのユーザーさんにRettyを利用していただいているためRettyには大量の食領域のデータがあります。このデータは非常に有用であり他企業や官公庁などのクライアントがこのデータを活用したいと思ってくださっています。しかし、生のデータだと扱うのが難しいのでFDPでは整形や統計値への変換をしたうえでデータを提供しています。
FDPの概要について説明すると、まずメディア系サービスであるRettyで収集したデータを整形したり、統計をとったり、レコメンドアルゴリズムを使ってレコメンドデータを生成したりなどをして提供データを生成します。
つぎに、生成したデータをクライアントが保有するサービスと連携します。
こうすることで、クライアントが保有するサービスのデータのバリエーションが豊富になりサービスの質向上の助けになることができるプロダクトになります。
そのため、FDPは、大きく分けて2つの要素から構成されています。
1つ目の要素は、ETL基盤です。Rettyが保有するデータの収集(Extract)、収集したデータの加工(Transform)、加工したデータをFDP用のデータベースに挿入(Load)をするための基盤のことです。この基盤でクライアントの要求に応えられる価値あるデータを生成しています。
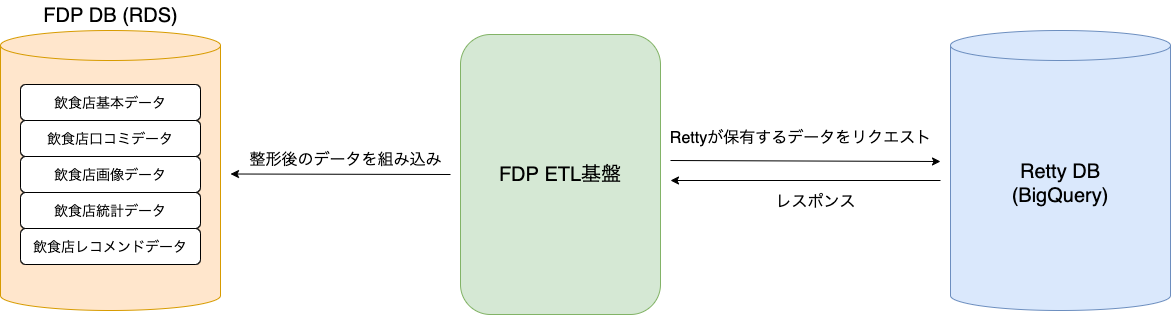
2つ目の要素は、APIサーバーです。こちらはETL基盤で生成したデータをクライアントが保有しているサービスにシームレスに連携するための機能となります。
FDPについてこれ以上詳しく説明すると長くなってしまうので、気になる方はこちらを色々と漁ってください!(宣伝は基本ですよねw)
FDPのETL基盤の課題
これまでのFDPは、Rettyが保有するデータをクライアントに提供するプロダクトでした。それに伴いETL基盤もRettyのDBからデータを取得して加工し、FDPのDBに組み込むことを想定した設計となっていました。
そんな折にあるクライアントから「自社で保有するデータとRettyのデータを組み合わせた状態で提供して欲しい」という要望を頂きました。 しかし、これまでのETL基盤では、Rettyが保有するデータ以外のデータ(外部データ)を取り扱うことができなかったため、ETL基盤で外部データをFDP DBに取り込む機能を追加をする必要がありました。
(以後、外部データを提供してもらうクライアントのことを外部クライアントと呼びます。)
preprocessETL基盤の設計
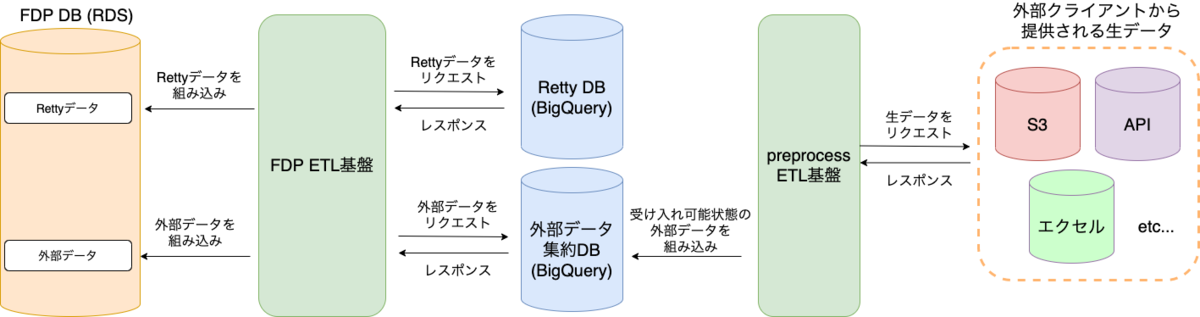
外部クライアントごとに生データの提供方法が異なるため、FDP DBに取り込みやすくするための前処理を行う別のETL基盤(FDP preprocessETL基盤)を用意することにしました。
これにより、preprocessETLを経て外部データを1つのデータソース(外部データ集約DB)で管理できるようにしました。
そして、FDP ETL基盤は外部データ集約DBから外部データを取得して加工し、FDPのDBに組み込めるようになりました。
configによる具体的な処理を設定
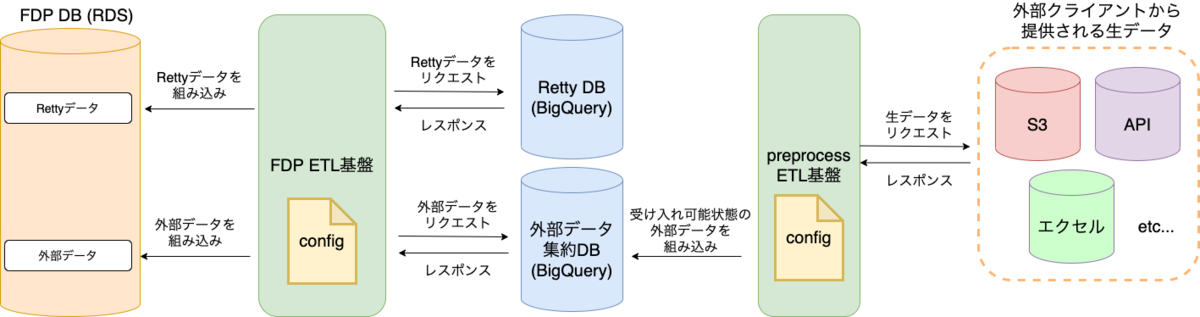
FDP preprocessETL基盤とFDP ETL基盤の外部データを取り扱う機能は、外部クライアントが今後増えていくことを想定した設計をしました。 外部クライアントが増えてもソースコードは増えない(なんて素晴らしいんだw)を理想型として設計しました。
FDP preprocessETL基盤とFDP ETL基盤の外部データを取り扱う機能は同様の設計をしており、Extract、Transform、Loadでそれぞれフレームを作り、そこに具体的な処理を設定ファイルで指定することでデータの取得・加工・組み込みをおこなうようにしました。
下記に設定ファイルの例を示します。
config = {
'extract': {
'data_warehouse': {
'service_name': 's3',
'bucket_name': 'hogehoge',
'source_files': [
{
'file_name': '外部データA.csv',
'file_path': 'external/クライアントA/'
},
{
'file_name': '外部データB.csv',
'file_path': 'external/クライアントA/'
}
]
}
},
'transform': {
'transform_functions': [
'外部データにIDを付与する関数',
'外部データにnameを付与する関数',
'外部データと外部データを結合する関数'
]
},
'load': {
'data_warehouse': {
'service_name': 'bigquery',
'table_info': 'external_project.クライアントA_dataset.外部データAandB_table'
},
'load_functions': [
'外部データのINSERT処理をする関数',
'外部データのUPDATE処理をする関数'
]
}
}
この設定ファイルでは、下記の処理をするための設定が記述されています。
- Extract
- S3からクライアントAの外部データAと外部データBを取得する
- Transform
- 下記のような加工をおこなう
- 外部データAと外部データBにIDを付与する
- 外部データAと外部データBにnameを付与する
- 外部データと外部データを結合する
- 下記のような加工をおこなう
- Load
- 加工したデータをBigQueryの'external_projectのクライアントA_datasetの外部データAandB_tableにINSERT処理とUPDATE処理をする
このように設定ファイルでETLの処理内容を設定してFDP preprocessETL基盤とFDP ETL基盤の外部データを取り扱う機能に読み込ませてデータ整形ができるようにしました。
これにより、今後外部クライアントが増えても設定ファイルを作るだけで外部クライアントの外部データをFDPに取り込むことが可能になりました。
おわりに
現時点(2020/12/20)では、設定ファイルで指定する処理(transform_functionsなど)のパターンがまだ少ないので、しばらくはソースコードを追加していく必要があります。
Extract系の処理の場合は、我々がまだ未対応のデータソースを外部クライアントが指定してきたときに追加実装が必要になります。 Transform系の処理の場合は、外部クライアントの要件を満たすように外部データを加工する必要があるので汎用性を持たせるのはかなり大変ですが徐々に共通処理が見つかり共通化できるようになると思います。 Load系の処理は、現状のFDPのアーキテクチャが変更されないかぎりは特に追加コードは必要ないと思います。
今後は、外部クライアントの要望に合わせて設定ファイルで指定する処理を追加していく予定です。 そのため、外部クライアントが増えていくたびに追加コードの量は徐々に減っていくと思います。
なのでいつか理想とした外部クライアントが増えてもソースコードは増えないにたどり着けると思います!(設定ファイルの管理が大変になる問題が出てくるかもしれませんが、、w)