今年もはじまりました Retty Advent Calendar 2020 !
初日を担当いたします技術部の西村です。
昨年は Aurora 移行に関する記事を 2 つ書きました。
Amazon Aurora 移行大全 #1
Amazon Aurora 移行大全 #2
今年も別サービスでの Aurora 移行を進めておりますが、昨年同様バグっぽい事象を踏んで上手く進まず、 AWS サポート問い合わせしながら対応してます。
(無事終わるかな...
さて技術部では色々な仕事がありますが、私は運用の自動化であったり、マネージドサービスだと一部要件を満たさないような機能の隙間を作ったりするのが好きです。
今回は良い感じに作ったツールの運用でサービスがすべて止まる悲劇を引き起こしたのでご紹介します。
起
弊社は Go To Eatキャンペーン に参画していることもあり、ありがたいことにリクエストが増えている状況でありました。
RDS などは事前に最小台数を増やして対応しておりましたが、通常とは違う挙動が確認できました。
CPU が限りなく 100% に近く、サービス影響が出始めていました。
アクセスログを分析すると下記であり、アタックのように見受けられました。
承
上記事象を解消するためには WAF を利用するのが良い案ですが、とある事情から難しかったので別案が必要でした。
1 nginx の rate limit 機能の利用 / Rate Limiting with NGINX and NGINX Plus
弊社は URL に応じたバックエンドの変更や静的ファイルのキャッシュなどで nginx を利用しており、そこで流量制限をかけようと思いました。
ただ複数台で構成されているため、バランシングしている環境では有効な設定ができるかと疑問でした。
またこの nginx ではかなりいろいろな設定を施しており、動作検証時間を考えるとこの案は難しそうでした。
2 mod_doshelper の利用 / doshelper
アプリケーションサーバでは Apache HTTP Server が起動しており、この mod_doshelper を利用することでバランシングされた環境でも上手く対応してくれます。
ただアタックのリクエストをこのアプリケーションサーバまで通過させるのはナンセンスなのでこの案は不採用です。
3 要件を満たすように自作
取り急ぎは検知ができて遮断ができれば良いので自作することにしました。
IP アドレスの取得
全リクエストを受ける ECS 環境があり、そのログから条件に満たす情報を取得するようにしました。
$ aws logs start-query --log-group-name '/ecs/test' --start-time $(date -d '10 minutes ago' +%s) --end-time $(date +%s) --query-string 'filter uri like /^\/hoge\// | stats count(*) as cnt by remote_ip, bin(1m) | sort cnt desc | filter (cnt>2000) | filter remote_ip != "unknown"' | jq .[] | xargs -I@@ echo aws logs get-query-results --query-id @@
仕様は下記の通りです。
- ロググループが
/ecs/testである - 10 分前から現在までの時間で抽出
- URI に
/hoge/が含まれるリクエストが対象 remote_ipベースに 1 分毎に集計- 2000 回以上を出力
結果の確認
上記実行後に出力された内容を実行すると下記のような出力になります。
ログの流量によってはすべて出力されるのに時間がかかるので "status": "Complete" であることを確認してください。
$ aws logs get-query-results --query-id xxxxx-xxxxx-xxxxxx-xxxxx-xxxxx | jq -r '.results[][] | .value' 192.168.0.1 ※ remote_ip 2020-10-07 01:47:00.000 ※ 時間 2586 ※ 1 分のリクエスト数 192.168.0.1 2020-10-07 01:48:00.000 2081 192.168.0.1 2020-10-07 01:44:00.000 2078
※ remote_ip は適当に変換してます
国コード確認
サービスの性質上、国外からのアクセスは基本的に無いので、whois で国コードを確認し、もし仮に国外であれば遮断しても良いかも、な判断をしてます。
ネットワーク ACL で遮断
遮断して良い IP アドレスであればすべての通信を許可する 0.0.0.0/0 ALLOW のルール番号より小さいルール番号を指定して DENY の設定を書きます。
場合によっては当該 IP アドレスを所有するプロバイダーの IP アドレス帯で遮断します。
事後処理
遮断後は、サービス確認、また遮断した IP アドレスを再度許可するか検討もする必要があります。
上記内容をドキュメント化して実装しました。
とりあえず動かしたかったので、ネットワーク ACL 部分の自動化は避けてその他を実装する形にしました。
Kubernetes の CronJob 利用して 5 分毎に実行し、条件に当てはまった場合には Slack 通知するようにしました。
※ ECS から CloudWatch Logs への転送のラグを想定して、スクリプトの実行間隔は抽出する時間より短めに設定してます。
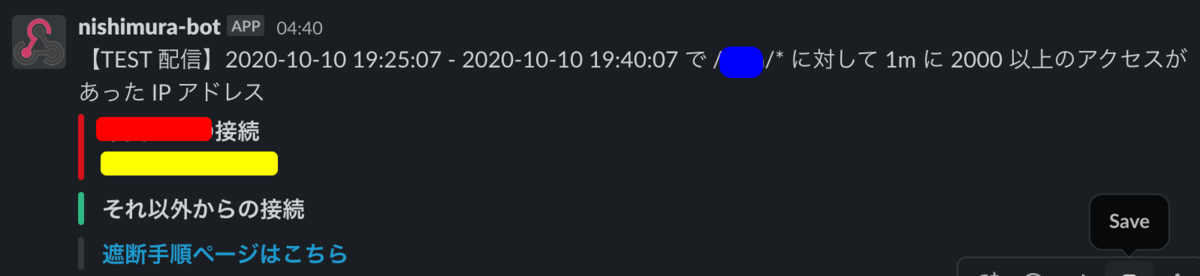
※ アタックを確認したときには特定の国からだったので、その国と、それ以外で分けて通知してます。
この通知を元に、
- 継続的に通知確認される
- サービス影響がある
などの条件を元にドキュメントを参考にしてネットワーク ACL で遮断します。
転
1 ヶ月ほど運用しており、適宜手動で対応しておりました。
勘の良い方は分かったかと思いますが、はい、サービス断を発生させてしまいました。
誤って 0.0.0.0/0 ALLOW を削除してしまいました。
ユーザ影響が発生し、PagerDuty は鳴るし、かなりの人数の方に動いてもらいました。
あとこの仕組を作った私ではなくて、他の方にミスをさせてしまったことが本当に申し訳ないです。
結
削除したルールを戻して復旧させました。
また遮断していた IP アドレスはすべて AWS WAF へ移動させました。
なぜオペレーションミスが発生したかというと、この仕組を作った私の目線のみ記載すると、
- ネットワーク ACL のインバウンドで設定できる数はデフォルトで 20 であることへの理解
- サービスを断させる可能性があることへの言及
- 手動運用ではなく自動化を行う
が足りてなかったと思います。
ネットワーク ACL のインバウンドで設定できる数はデフォルトで 20 であることへの理解
障害当時に上限に達してエラーになったため作業者を困惑させてしまい、またアタックが継続しているという異常な状態がオペミスを誘発させてしまったと思います。
上限の理解があると無限に登録できないので、運用そもそもの見直しが必要だったかと思います。
サービスを断させる可能性があることへの言及
ドキュメントをどこまで書くかはチームの成熟度によって変わると思いますが、サービス影響あるなしの言及は必須だと思いました。
手動運用ではなく自動化を行う
自動化がすべて解決するわけではないですが、少なくとも安心・安全への意識をより高め手動運用を減らす努力をしていく必要があると思いました。
ここまで読んでいただいてありがとうございます!
明日以降の Retty Advent Calendar 2020 もどうぞよろしくお願いします。