はじめに
2022年10月からVPoEになりました常松です。入社以来3年間、RettyのWeb開発を見てきましたが、10月からインフラチームのマネージャーを代わり務めることになりました。インフラ整備・運用周りの取り組み発信はこれまでも行っていたものの、社内的にはどんな位置付けのチームで、これからどんなことに取り組もうとしているのか整理して公開できていなかったため、本記事で紹介します。
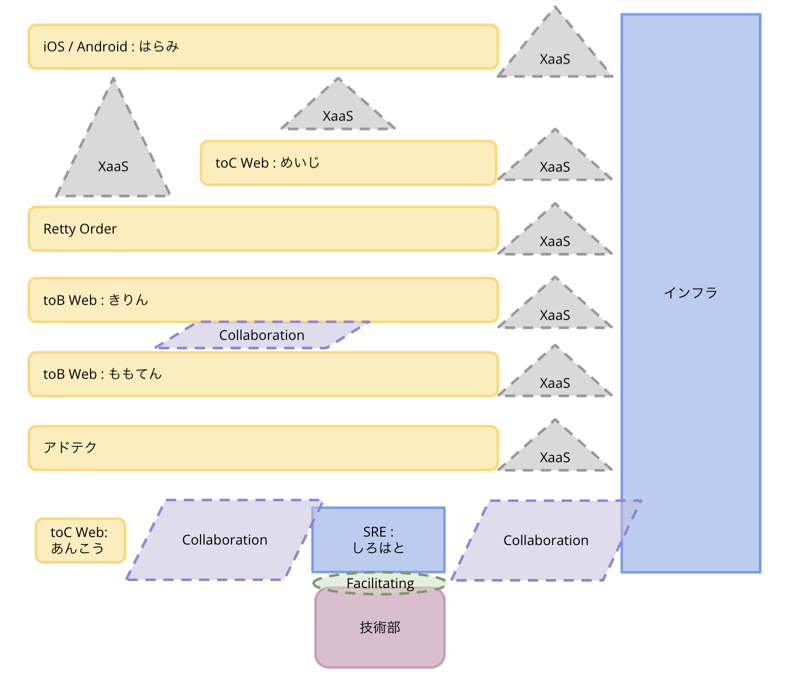
インフラチームの位置付け
サービスの技術スタックや利用しているSaaSはカジュアル面談資料にまとめていますのでそちらを参照ください。
チームが担う責務
Rettyの開発体制といえば大規模スクラム(LeSS : Large Scale Scrum)を取り入れていることを継続的に発信していますが、インフラチームはこのLeSS開発の流れには入っていません。これはサービス開発を行うチームの中にインフラ知識のあるメンバーが一定数おり、インフラエンジニア無しにデリバリーができるためです。インフラチームはデータ基盤などと同様、複数のチームを横串で支える存在です。
(参考) チームトポロジーを用いたRettyプロダクト開発体制の解説 #ちいとぽ - Retty Tech Blog
一方でインフラチームを置かないと、サービスの横串の統制が取りづらくなり、少しずつ運用工数やインフラコストが増大していってしまいます。 良い取り組みを素早く横展開していくにも、整理整頓して管理を行き届かせるためにもインフラチームは必要な存在です。
また年に何回かはAWSやSaaSサービスのサポートが必要になるような難易度の高いトラブルや困りごとも発生します。 こういったやりとりもインフラチームのエンジニアが巻き取り、他チーム・エンジニアがサービス開発に集中できるようにします。
オンコール担当
Rettyは24時間365日休みなくユーザー・お店にサービスを提供しています。そのため休日・夜間の障害連絡(=オンコール)に対処するチーム・仕組みがあります。 インフラチームと開発チームの代表者が混成のチームを組み、1週間交代で万が一の対応に備えています。 オンコール担当だけが孤軍奮闘するのではなく、担当はあくまで連絡の一時受けで対応は手が空いている・気がついたメンバーが自発的に協力して対応しています。また障害のふりかえり(ポストモーテムの執筆と読み合わせ)や、根本対応も当たり前のこととして根付いており、年単位で見て障害の発生回数や障害の継続時間は減少傾向にあります。
運用週のしくみ
インフラチームはサービス開発チームからの相談(権限付与や、リソース作成・設定変更などの依頼)と並行し、腰を据えて取り組む必要がある重めの技術課題の対処も抱えています。そのためサービス開発チームからの相談を受ける担当を決め、1週間交代でローテーションする運用週の仕組みを設けています。このためまとまって調査・作業を進める時間が作れるようになり、後述する大きめの技術課題の解消が着実に進められるようになりました。
サービスを安定稼働させるために
Rettyのインフラチームに根付いている基本的な考え方として「新しいもの・便利なものを積極的に取り入れ、サービスの安定稼働に結びつけていく」というものがあります。自分達で全て作る・用意するのではなく、既にある良いもの・可能性を感じる新しいものがあれば積極的に取り入れ自分達の負担を下げていきます。
過去の取り組み事例からもその思想が垣間見えるかと思います。
[2019年]
- Aurora移行 (※ 2021年にオートスケールの仕組みも導入)
[2020年]
- 社内開発環境をEKSで構築
[2021年]
- Fastlyを使ったページキャッシュ機構の置き換え
- FastlyのWAFサービス(Fastly Next-Gen WAF powerd by Signal Sciences)を導入
- Pull Request毎の検証環境の自動構築
[2022年]
- Terraformによるマイクロサービス環境の構築
今後取り組む大きな課題
今後1〜3年ぐらいで対処していきたいと考えている、大きめの課題を紹介します。
AWSマルチアカウントの推進
Rettyはサービス開始から10年が経ち、創業時からのモノリスをマイクロサービスへ移行している道半ばです。toC / toB両領域でサービスの分割は粛々と進んでいますが、これに伴いサービスアカウントの分割や、Production / Staging / Develop環境の適切な分割、データベースの分割はまだこれからの状態です。
マルチアカウントに分割することで、コストの可視化が容易になり、権限整理もあわせて進むと考えています。 新規のサービスインフラ整備はTerraformに寄せているため、ある程度整備が進んだ段階でアカウントと環境を分割・新設し、推進していく形になるかと思います。
セキュリティの強化
WAFの導入、操作ログの記録、権限やリソースの定期的な棚卸は粛々と行っておりますが、世のベストプラクティスとされている取り組みに追いつくにはまだまだやるべきことがあります。
例えば新サービス開発ではGraphQLを積極的に採用していますが、GraphQL Inspectionの導入は来年にも検討したいと考えております。
またユーザー・お店への連絡にメールを使う機会がありますが、メールの信頼性を向上させる為の施策としてSESとRoute53でSPFとDKIMを設定しています。 しかしさらなる信頼性向上のためDMARC(Domain-based Message Authentication, Reporting, and Conformance)、およびBIMI(Brand Indicators for Message Identification)の導入を検討しています。
ログ転送・集計基盤のモダナイズ
ユーザー分析に関するログの収集・転送・集計をする仕組みは内製のものを使っていますが、送信側・転送側それぞれに課題を感じており、自前運用からの脱却を検討しています。Googleアナリティスク4が置き換え候補ですが、移行過程でログを漏らさずビジネスを止めないようにするには既存基盤を微修正しながら対応する必要があります。
サービス稼働に関する動作ログの方もCloudWatch Logs / S3 / Datadog などあちこちに散らばってしまっており、ログを集約・整理して検索しやすいようにしたいと考えています。
その他
不要なインフラリソースの整理、インフラコストの削減も継続的に取り組んでいきます。 半年〜1年内だとDB(Aurora) / ECS FargateのプラットフォームをGraviton2に順次置き換えていく予定です。
おわりに
飲食業界を盛り立てていくための縁の下の力持ち、募集しています。 カジュアル面談からお待ちしております。