本記事はRettyアドベントカレンダー2024の9日目の記事です。
Rettyでエンジニアリングマネージャを務めている山田です。
2022年の年末頃にChatGPTが登場してから早2年となります。 当初は革新的なAIという印象でしたが、時間の経過によりLLMを普段の生活や業務に活かしたり、これを応用したアプリケーションの開発を検討するなど、こうした発明もある程度浸透してきている頃合いではないかと思います。
特に、LLMは任意の自然言語形式のデータの取り扱いに優れ、これまで実現が難しかったアイデアを形にすることができるため、LLMを応用して新しい体験を提供する機能の開発に取り組んでいる方や、すでにリリースされている方も多いでしょう。 一方で、LLMの活用を考える上で、コストの問題や長いレスポンスタイム、特にクローズドなモデルの場合挙動が時間経過で微妙に変わってしまうなど、特有の困りごとに直面することも多くなります。
そんな時に、旧来から存在するベクトル検索のアプローチを再考したくなります。テキストや画像をベクトルに変換し、ベクトル同士の比較で類似のコンテンツを発見するベクトル検索は、LLMよりも安く、早く、ベクトル化に用いるモデルのサイズも小さいので、ローカルでも動かしやすく挙動を制御しやすいです。 LLMと同様にベクトル化の精度も日進月歩で進化しており、より大規模なデータに対しての分類や類似検索のようなアプローチには総合的にはLLMに勝るところもあります。
本記事では、そんなベクトル検索を実現する上で必須となるベクトル検索に対応したDBのうち、特に検討されがちな「Qdrant」と「pgvector」を比較し、それらのユースケースについて考察を行います。
なお、DBの比較なので厳密には拡張機能であるpgvecorではなくPostgreSQLと書くべきではありますが、ベクトル検索に着目しpgvectorにフォーカスを当てた記事であるため、わかりやすさを重視して便宜上PostgreSQLと書くべき箇所でpgvectorと記述しています。
性能比較の前提
今回の性能比較は全て以下のような性能のマシン上で行いました。
| 種別 | 諸元 |
|---|---|
| OS | macOS 15.1.1 |
| CPU | M2 Pro |
| RAM | 32GB |
また、それぞれローカルマシン上にてRancher Desktopを利用したDockerで動作させており、以下のイメージを利用しています。 それぞれのイメージ内で動作しているアプリケーションのバージョンも記述しています。
- Qdrant
- qdrant/qdrant
- Qdrant v1.12.4
- qdrant/qdrant
- pgvector
- pgvector/pgvector:pg17
- PostgreSQL 17.0
- pgvector 0.8.0
- pgvector/pgvector:pg17
Rancher Desktopの仮想マシンには以下のリソースを割り当てました。
| 種別 | 諸元 |
|---|---|
| CPU | 4コア |
| RAM | 12GB |
今回の比較検証のため、768次元のベクトルデータを101,899件集め、以下のようなデータを作成しました。
| データ名 | 概要 |
|---|---|
| id | 連番の数値によるID。各要素ごとにユニークな数値を0 ~ 101898まで設定 |
| vector | 768次元のベクトルデータ |
| option | フィルタを利用した際の検証のための適当な数値。1~5の値からランダムに設定 |
このようなデータをそれぞれ以下のようなスキーマで投入します。
pgvector
create table contents ( id integer not null primary key, vector vector(768), option integer );
Qdrant
| データ名 | Qdrantでの取り扱い |
|---|---|
| id | レコードごとのidとして投入 |
| vector | レコードごとのベクトルデータとして投入 |
| option | payloadとして投入 |
最後に、検証に利用するスクリプトはPython 3.12.4で記述しており、以下の依存を用いています。
psycopg==3.2.3 psycopg_binary==3.2.3 pgvector==0.3.6 qdrant_client==1.12.0
性能比較の結果
実際に性能比較を行ってみましょう。
「性能比較の前提」の項目の通りに用意されたDBに対し、特定のタスクを達成するクエリを1,000回実行するスクリプトを3回実行し、その実行時間ごとの平均、最短、最長時間を用いて比較を行います。 それぞれの結果をまとめてみました。
インデックス無し
まずはインデックスを利用しない場合から比較します。通常ベクトル検索は高速化のためにインデックスを作成し、近似での検索を行います。 この項目ではインデックスを使わない代わりに正確なベクトル検索を実施した場合のパフォーマンスをチェックすることになります。
pgvector, Qdrantそれぞれ以下のようなスクリプトによりランダムに指定したベクトルに類似するレコードを取得します。なお、pgvectorについては自身も含んで取得してくるため、自身以外のレコードを5件取得させるためにLIMITを6としています。
pgvector
content_id = random.randint(0, 101898) query = f""" SELECT id FROM contents ORDER BY vector <=> (SELECT vector FROM contents WHERE id = {content_id}) LIMIT 6; """ cursor.execute(query)
Qdrant
content_id = random.randint(0, 101898) qd_client.query_points( collection_name="contents", query=content_id, with_payload=False, limit=5, search_params=models.SearchParams(exact=True), # デフォルトでインデックスを活用するので、明示的に厳密な検索を指定し、インデックスを使わないようにします )
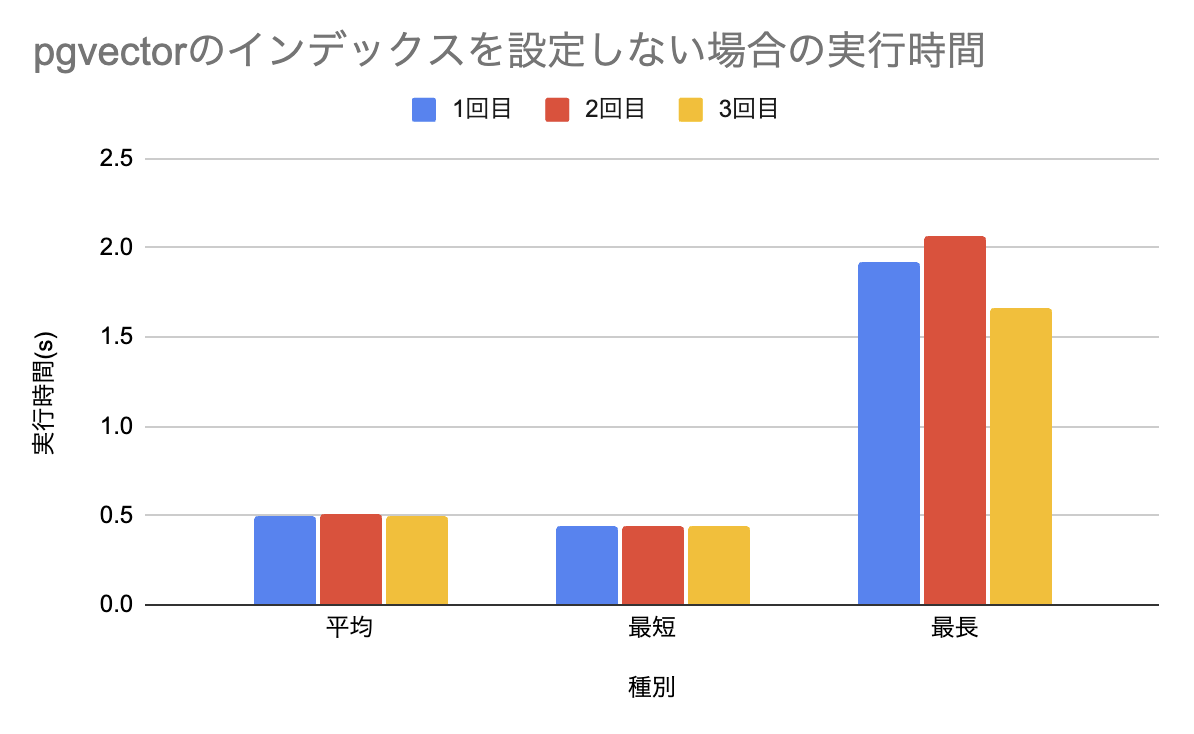
これについての実行結果が以下の通りです。
pgvector
Qdrant
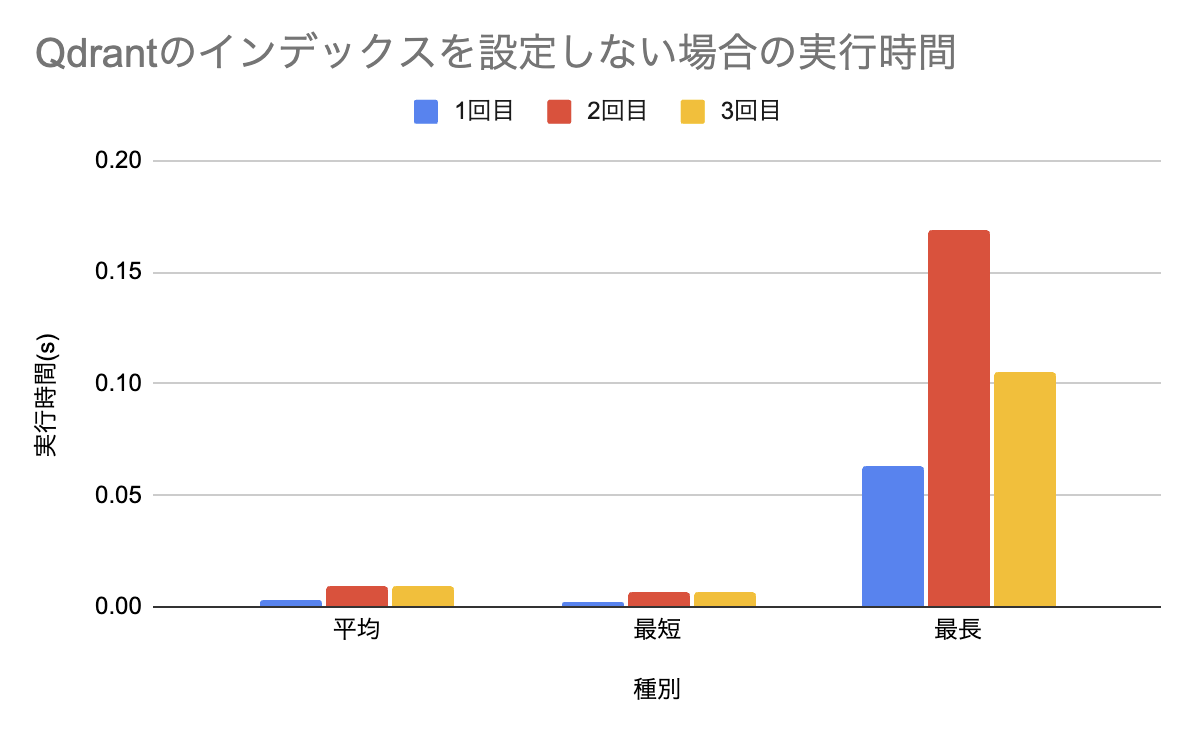
なお、この項目のみオーダーが違いすぎてまとめることができなかったので、pgvectorとQdrantのグラフを分けています。 見ての通り、pgvector比較でQdrantは桁が一つ違うパフォーマンスを発揮しており、近似に頼らない厳密な検索を行う場合にはQdrantが適していると言えるでしょう。
実行結果の詳細
pgvector
| 回数 | 平均 | 最短 | 最長 |
|---|---|---|---|
| 1回目 | 0.495717 | 0.440761 | 1.924180 |
| 2回目 | 0.506840 | 0.446878 | 2.070112 |
| 3回目 | 0.492702 | 0.444169 | 1.663335 |
Qdrant
| 回数 | 平均 | 最短 | 最長 |
|---|---|---|---|
| 1回目 | 0.003228 | 0.001982 | 0.063173 |
| 2回目 | 0.008978 | 0.007104 | 0.169054 |
| 3回目 | 0.009152 | 0.007024 | 0.105390 |
インデックスあり
次に、インデックスを設定する場合を試します。実行するスクリプトはほぼそのままで、インデックスが使用されるように設定を施します。
まずpgvectorについては以下のクエリでHNSWによるベクトルインデックスを設定します。なお、mやef_constructionの値はより適した値があるとは思いますが、そこまで凝ったチューニングはしていない点にはご注意ください。
CREATE INDEX ON contents USING hnsw(vector vector_cosine_ops) WITH (m = 16, ef_construction = 64 );
次に、Qdrant側もパラメータをpgvector側に揃えるための設定を行います
qdrant_client.update_collection(
collection_name="contents",
hnsw_config={
"m": 16,
"ef_construct": 64,
"full_scan_threshold": 10000
}
)
また、先ほど用いたスクリプトではsearch_paramsにインデックスを利用しないような設定なされていたため、これを修正しインデックスを活用するようにします。
search_params=models.SearchParams(exact=False),
これで準備は整いました。その結果が以下の通りです。
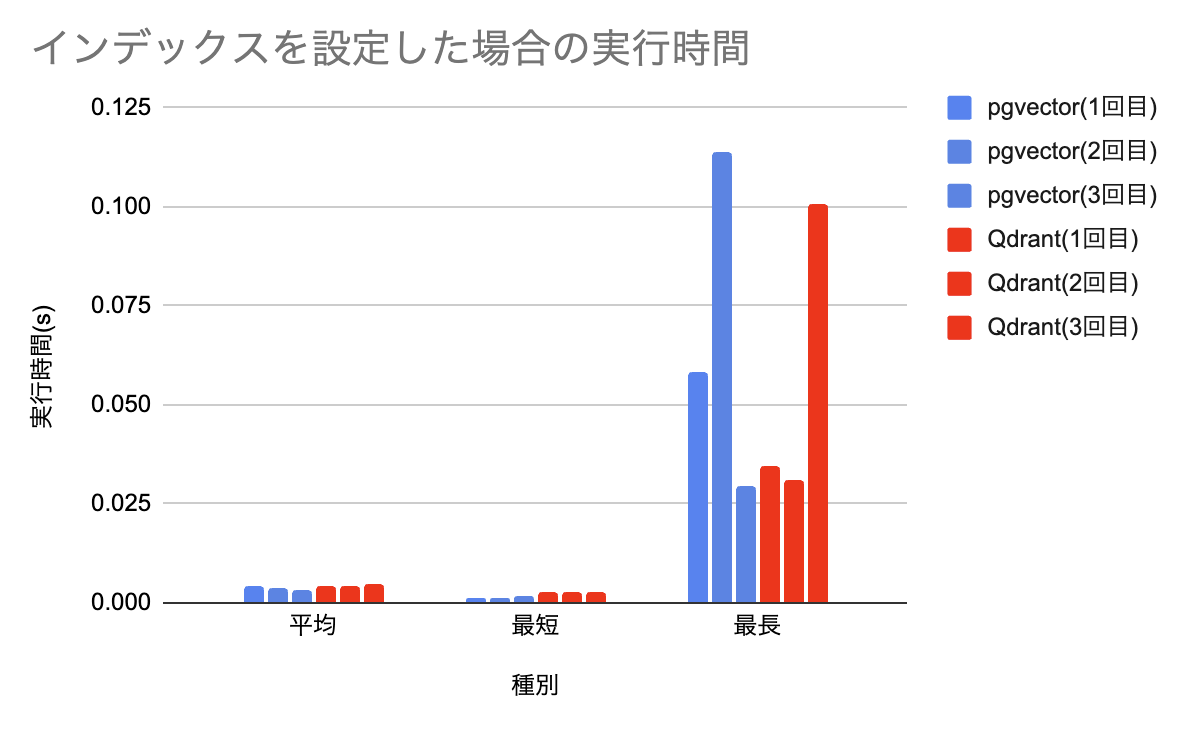
最長実行時間は長短ありますが、全体としてpgvector側が少し優位かな?と読めそうです。
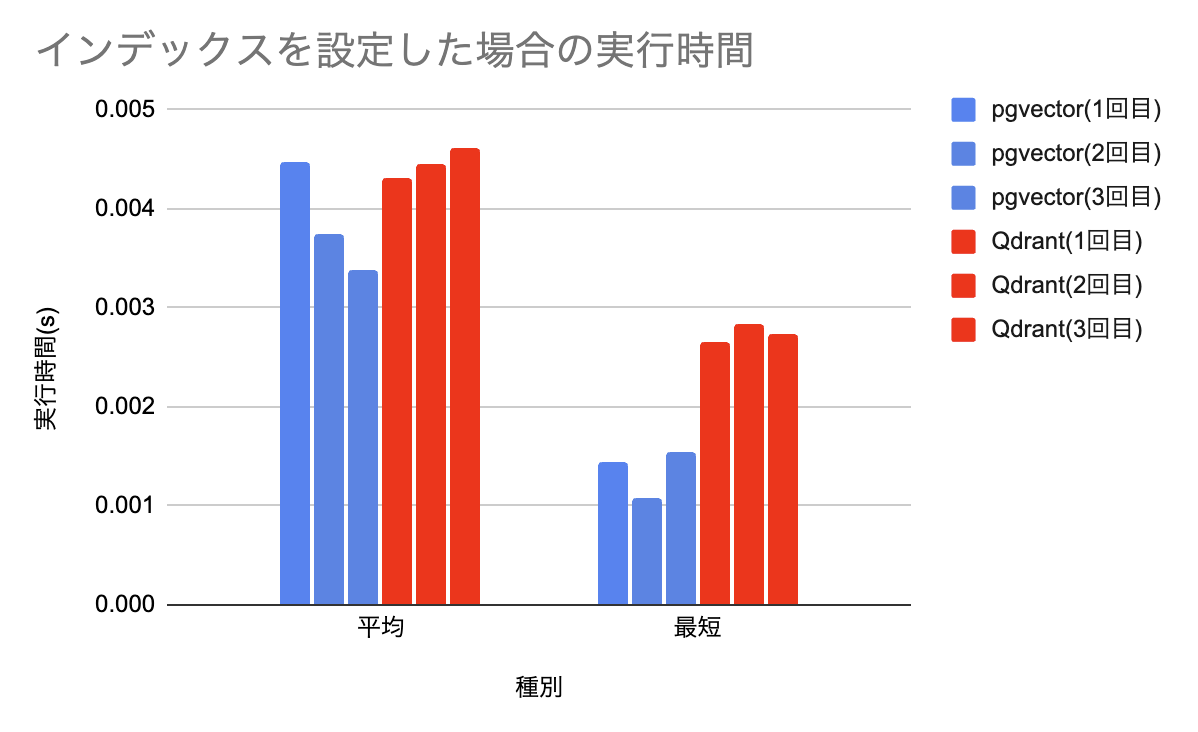
最短・平均実行時間の部分だけ抜き出してみます。平均はそこまで大きな差はないですが、最短実行時間はpgvector側が半分ほどになっています。おそらくキャッシュがうまく働くとこのような速度が出せるのだろうと推測できます。
実行結果の詳細
pgvector
| 回数 | 平均 | 最短 | 最長 |
|---|---|---|---|
| 1回目 | 0.00447 | 0.001436 | 0.058229 |
| 2回目 | 0.003749 | 0.001085 | 0.113933 |
| 3回目 | 0.003385 | 0.001548 | 0.029274 |
qdrant
| 回数 | 平均 | 最短 | 最長 |
|---|---|---|---|
| 1回目 | 0.004303 | 0.002656 | 0.034420 |
| 2回目 | 0.004457 | 0.002847 | 0.030823 |
| 3回目 | 0.004606 | 0.002737 | 0.100613 |
フィルタを含むクエリでインデックスあり
最後に、これまで試したクエリよりも、より実戦を意識した複雑なクエリでの挙動を確認します。 実際のプロダクトでは、ベクトル検索だけで完結することはそう多くなく、何らかのフィルタリングを併用する事がほとんどです。例えばECサイトを想定すると、特定の商品のベクトルだけを比較して類似商品を検索するのではなく、商品に設定した種別や価格設定等でフィルタリングを行い、ベクトル検索を行いたくなることでしょう。こうすることで、ベクトル検索の動作をより厳密なものとしつつ、さらに関連性が高く、ニーズを満たすレコメンドを制御しやすい形で実現する事ができます。
今回の検証では、以下のような仕様を想定します。
- ランダムに指定したIDのベクトルと類似するレコードを取得
- ランダムに設定された4つのoptionを用いてフィルタリングを行う
- 類似度の上位500件を取得
これまでただランダムに指定されたベクトルとの類似度を計算するだけのものに比べるとより複雑になり、取得件数もグッと増やしました。これをコードに落とすとそれぞれ以下のようになります。
pgvector
content_id = random.randint(0, 101898) options = random.sample(range(1, 6), 4) query = f""" SELECT id FROM contents WHERE option = ANY(%s) ORDER BY vector <=> (SELECT vector FROM contents WHERE id = %s) LIMIT 501; """ cursor.execute(query, (options, content_id))
Qdrant
content_id = random.randint(0, 101898) options = random.sample(range(1, 6), 4) query_filter = { "must": [ {"key": "option", "match": {"any": options}} ], } qd_client.query_points( collection_name="contents", query=content_id, with_payload=False, query_filter=query_filter, limit=500, )
pgvectorはこうしたフィルタ処理については見慣れたSQLになりますので、特段の補足は不要かなと思います。Qdrantについてはquery_filterというものを用いてフィルタリング処理を設定する事ができます。ただ、これもQdrant独自だから難しいというわけではなく、Elasticsearchのものを参考にしているようで、かなり酷似している事がわかります。Elasticsearchの経験がある方であれば、Qdrantも難なく扱えるのではないでしょうか?
optionを用いるため、これに対してのインデックスも設定します。それぞれ以下のようなクエリになります。
pgvector
CREATE INDEX ON contents(option);
Qdrant
qdrant_client.create_payload_index(
collection_name="contents",
wait=False,
field_name="option",
field_schema=models.IntegerIndexParams(
type=models.IntegerIndexType.INTEGER,
lookup=True,
range=False,
),
)
pgvector側はお馴染みのインデックスを張るクエリです。Qdrantもこのように記述することでベクトル以外のpayloadに対してもインデックスを設定できます。lookupは値の一致を確認する場合、 rangeは範囲でのフィルタを利用する場合にそれぞれTrueとすると良いようです。今回は値の一致を見るのでlookupのみをTrueとします。
なお、pgvectorについてはこうしたクエリを実行する前に事前準備が必要で、今回のフィルタを含むクエリの実行前に、hnsw.iterative_scanを設定する必要があります。これを設定しないと意図した通りにクエリが動作しません。
さらに、hnsw.iterative_scanにはrelaxed_orderとstrict_orderの二種類があります。前者が厳密さを捨てて速く動作するモード、後者が厳密ですが遅いモード、という理解で問題ありません。
この設定は以下のようなクエリで行いました。
SET hnsw.iterative_scan = relaxed_order;
詳細は後ほど記述しますが、ひとまずそういうものという前提で読んでいただければと思います。
このような検証を行った結果が以下の通りです。
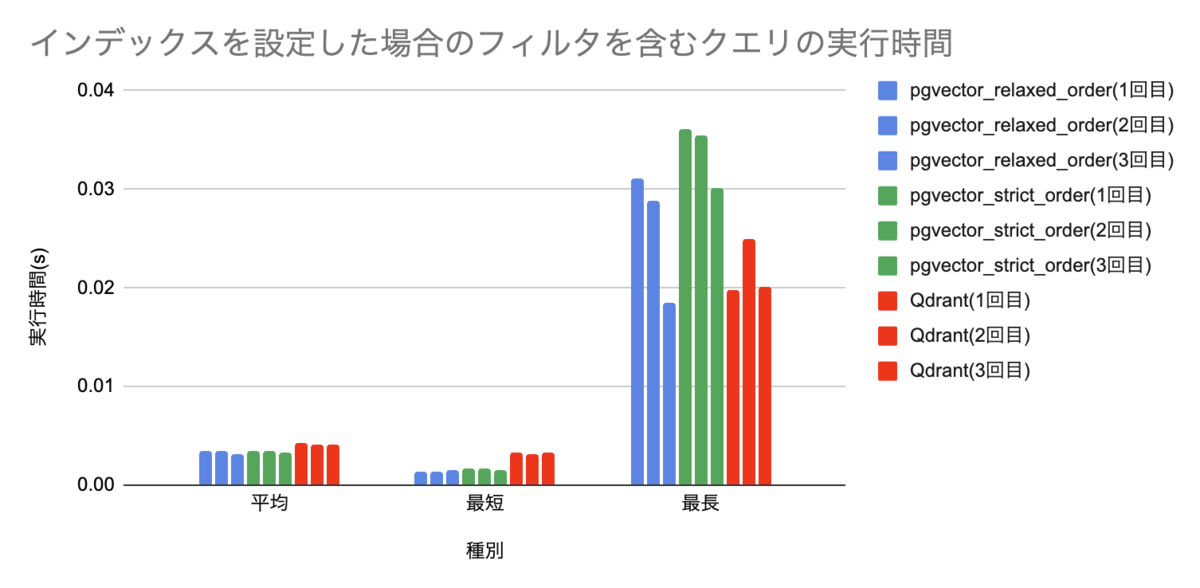
最長実行時間はQdrantが全体として落ち着いている印象がありますが、やはり平均・最短はpgvector側に分があるように感じます。
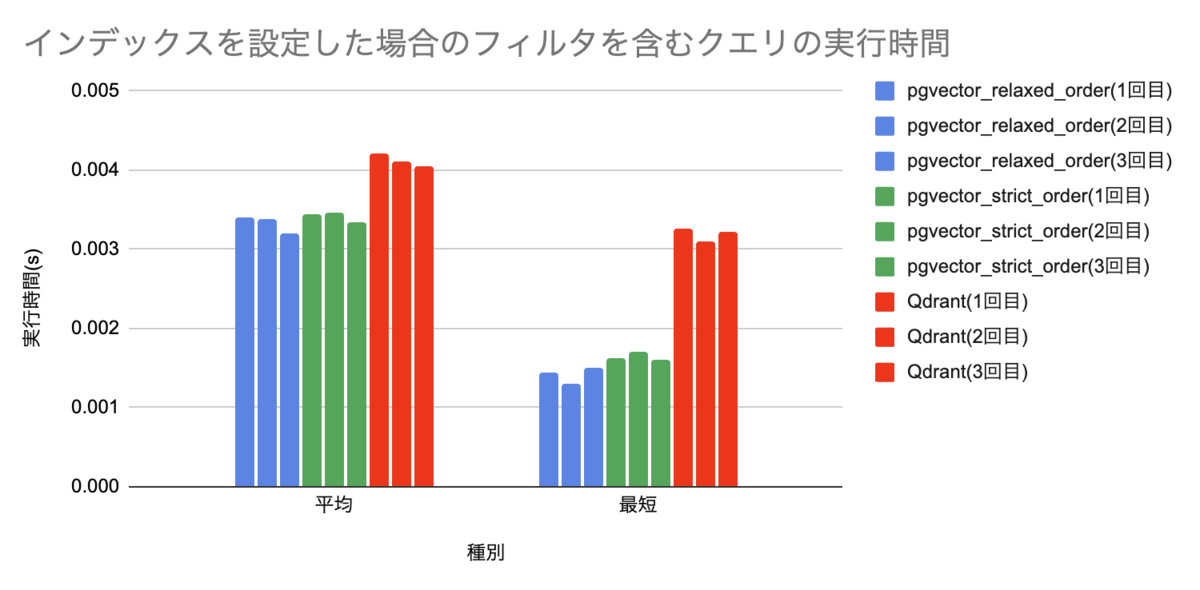
最短・平均実行時間の部分だけ抜き出してみます。やはりこうしたクエリでもpgvector側が速いという言う傾向には変わり無いようです。さらに、同じpgvectorでも、relaxed_orderを設定した方がわずかに速い事がわかります。
実行結果の詳細
pgvector(relaxed_order)
| 回数 | 平均 | 最短 | 最長 |
|---|---|---|---|
| 1回目 | 0.003404 | 0.001446 | 0.031067 |
| 2回目 | 0.003390 | 0.001306 | 0.028789 |
| 3回目 | 0.003197 | 0.001512 | 0.018559 |
pgvector(stricet_order)
| 回数 | 平均 | 最短 | 最長 |
|---|---|---|---|
| 1回目 | 0.00344 | 0.001635 | 0.036111 |
| 2回目 | 0.003469 | 0.001708 | 0.035501 |
| 3回目 | 0.003341 | 0.001599 | 0.030178 |
Qdrant
| 回数 | 平均 | 最短 | 最長 |
|---|---|---|---|
| 1回目 | 0.004207 | 0.003270 | 0.019818 |
| 2回目 | 0.004110 | 0.003095 | 0.024966 |
| 3回目 | 0.004056 | 0.003224 | 0.020168 |
pgvectorの精度の問題と、それを解決するhnsw.iterative_scanについて
この項目で実行したクエリを、hnsw.iterative_scanを設定せずに実行してみることを考えます。
以下のクエリは検証で利用したクエリの結果の数をカウントするクエリになります。コサイン類似度で順序付けしており、先頭から501件取得するように見えるので、このクエリの結果も501と言う値が返ってきそうです。
SELECT COUNT(*) FROM (SELECT id FROM contents WHERE option IN (1, 2, 3, 4) ORDER BY vector <=> (SELECT vector FROM contents WHERE id = 1) LIMIT 501) AS tmp;
しかし、hnsw.iterative_scanを設定しない場合、この結果は32になってしまいました。もちろんoption IN (1, 2, 3, 4)のフィルタでヒットする件数は501件を超える十分な量がありますが、非常に少ないヒット数となってしまいました。
これはあまりにも直感とは反する挙動です。なぜこのような挙動となってしまうのでしょうか?
原因が二つ挙げられます。まず一つ目はhnsw.ef_searchという設定のデフォルト値が小さいことです。まず前提としてpgvectorがHNSWによるベクトルインデックスを利用する場合の挙動を理解する必要があります。pgvectorはフィルタ処理を伴うHNSWのベクトルインデックスを利用したクエリを実行する時、先にベクトルインデックスを利用した近似検索を行い、それでヒットしたレコードに対してフィルタを行う、という順で処理がなされます。この時、全てのレコードに対してベクトル関連の計算を行っていると近似計算にならず、非常に遅くなってしまうため、近似検索によって取得できる件数は制限されています。この件数のことを ef_searchと言い、デフォルトでは40件と設定されています。
以上からこのクエリの処理の流れを解釈すると
- レコード全件からID1のベクトルに近似するベクトルを持つレコードの上位40件だけ取得する
- 1でヒットしたレコードに対し、optionが1,2,3,4のレコードのみを残すフィルタ処理を実施する
- 2の結果残ったレコードの上位501件を取得する
となります。これが想定よりもヒット数がずっと少なくなってしまう原因です。
では、このhnsw.ef_searchの値を大きくすると問題は解決するのではないか?と思いますが、そこまで単純な話ではなく、hnsw.ef_searchを大きくすることについては以下のような問題があります。
- ベクトル検索を実施した際の計算量が増えてしまう
ef_searchの設定値にも上限(1000)があり、それより大きい値に設定することはできない- 先にベクトル検索 -> 次にフィルタ処理という順序で処理を行う都合、検索精度の問題を解決できない
- 特にカーディナリティが高いカラムでフィルタを行う場合、ベクトル検索によりまず全体の上位で絞られてからフィルタを行う都合、所望の件数を満たせ無い可能性が高い
このef_searchの設定でも解決できない問題を解決し、原因の二つ目としても挙げられるものがiterative_scanになります。
この機能はpgvector 0.8.0で追加されたもので、指定した件数を満たすまで反復的にスキャンを繰り返すという挙動を実現するものです。今回のクエリの場合、501件を指定しているため、この501件を満たすまでひたすらスキャンを繰り返す、という挙動になります。
このアプローチの場合、HNSWのベクトルインデックスのパフォーマンス向上の恩恵を受けつつ、検索精度を向上する事ができるため、基本的には有効にしておくと良いでしょう。この機能はデフォルトでoffになっているため、明示的に設定しない限りはこのような挙動になってしまいます。
繰り返し実行するというところからパフォーマンスが悪くなってしまうのでは?という心配もありますが、本記事で検証した通りある程度十分な速さは備えているとみられるため、そこまで心配するほどではなさそうだ、と思っています。
このiterative_scanによって複数回スキャンした結果について、パフォーマンスをトレードオフとして順序を厳密に行うか緩く行うかを選択する事ができ、これを設定するのが strict_orderと relaxed_orderになります。用途に合わせて適したものを設定しましょう。
検証結果からわかる事
インデックスを用いない厳密な検索を行う場合にはQdrantが桁違いの圧勝でした。 ただ、インデックス抜きで10万件にも及ぶレコード全てに対して厳密な検索を行うケースというのが恐らくあまり無いだろうことは注意が必要です。 インデックスを用いる場合についてはpgvectorがより優れたパフォーマンスを発揮するようです。とはいえ、Qdrantが遅いというとそんなことはなく、どちらも非常に高速に動作するため、実際のアプリケーションに投入する際にこの性能差が響く事はあまりないでしょう。
Qdrant, pgvectorどちらを採用すべき?
本記事の検証結果から判明したパフォーマンスの観点で言うと、多少の差はありますがどちらも非常に高速に動作するため、実用上はどっちでも良いと言う結論にはなりそうです。あえてどちらか選ぶのであれば、気持ちpgvectorの方が早いくらいでしょうか?
一方で、パフォーマンス以外の点には多くの差があります。例えば pgvectorは多くのエンジニアが慣れ親しんだSQLで記述できます。PostgreSQLのエコシステムに存在するものなので、ある程度保守運用の知識も流用できます。任意のクライアントツールで扱えますし、AWSのAuroraからも使えるのでスケールしやすいです。このようにPostgreSQLの機能の一つであることに多くのメリットがあります。Qdrantについてはこの点まだまだPostgreSQLに比べれば新興にはなりますので情報も多くはなく、対応の難しいトラブルが発生する可能性も少なくないでしょう。
ここまで記述すると、運用しやすくて開発しやすくて、多少でもパフォーマンスが優位なpgvectorで良いのではないか?となりますが、実はそう言うわけでもありません。pgvectorはインデックスが使われれば非常に高速に動作しますが、インデックスが使われない場合は非常に低速です。そして、インデックスが使われるかどうかはオプティマイザが判断することになるため、うまくベクトルインデックスを使ってくれるようなテーブル設計、及びクエリ構築を行う必要があり、これを怠ると思ったようなパフォーマンスが出なくなってしまいます。こればかりはPostgreSQL自体やpgvectorの経験や知識が無いことにはうまくできないため、SQLで誰でも開発できるからpgvectorを採用すると言うのは実は早計と言うことです。
一方のQdrantは最初こそQdrant独自のクエリを学ぶ必要がありますが、おおよそ平易でありそこまで難しさを感じることはありません。さらに、pgvectorのような複雑な設計を意識しなくても常に高いパフォーマンスを発揮してくれます。新しいが故の不安ポイントこそありますが、総合的にはQdrantが扱いやすいと言えるのではないでしょうか?
以上から、ベクトル検索においてはPostgreSQLのエキスパートが協力でき、パフォーマンスを最大限発揮させたい場合にはpgvectorを、そうで無いのであればQdrantを採用するのが良いのではないかと考察します。
まとめ
本記事ではベクトル検索を実現するための技術としてpgvectorとQdrantの比較を行ってみました。
実は、pgvectorについてはある程度使い込んだ上で、もっと早くできないかと悩んだ末にQdrantの導入を検討していた背景もあり、pgvectorの方がパフォーマンス自体はQdrantを上回るという結果に対してはかなり意外に思いました。
というのも、これまで利用していたpgvector 0.7.xでは本記事で紹介したようなiterative_scanの仕組みが無く、これが適用できないケースにおいてはインデックスが利用できないのでパフォーマンスが相当に悪くなってしまうor検索精度が非常に悪化する、という問題があり、見事にこれを踏み抜いていた次第でした。
以前よりQdrantはそういった課題を解決しており、そちらに靡く気持ちがあったのですが、今回の検証によりpgvectorも進化しておりパフォーマンスを理由にして無理に移行する必要性も薄そうだという判断ができました。今回の件で当たり前の事ではありますが、やはり技術選定は印象や思いつきで進めるものではなく、きちんと定量的に測定し、正確な情報をもとに行うべきであるという大切なことを再確認しました。