概要
こんにちは、エンジニアの堤です。
先日、RettyのDB負荷を改善するプロジェクトが完了し、実際にDB負荷が大幅改善したのでご紹介します。
実際の対応としては、Rettyのまとめページに対して存在確認クエリの対象を、DBからRust製マイクロサービスに移行することでした。
本記事では、移行実施に伴う苦労と実施内容について記述します。
Rust製マイクロサービス構築については深くは触れませんのでご了承ください。
対象読者
以下に興味がある方
- 負荷軽減・コスト改善
- 大規模なレガシー環境からの移行
- 動的にコンテンツが増減するまとめページを持っている方
目次
成果
Rettyメディアで利用しているDBへの負荷: 利用時間ベースでリリース前後比70〜80%削減
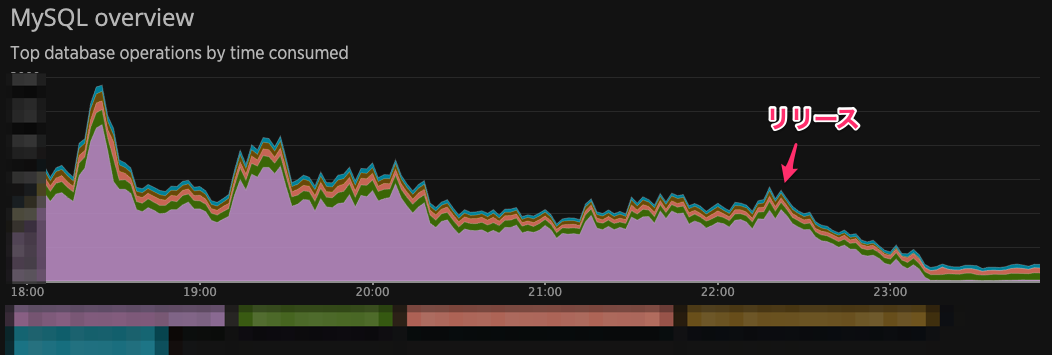
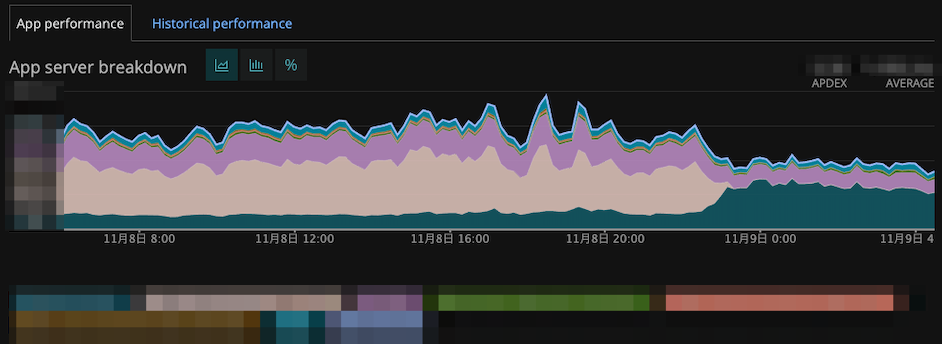
該当ページのレスポンス速度: 約1.5倍に
(CDNキャッシュを通さないアプリケーションへの直接リクエストの場合)
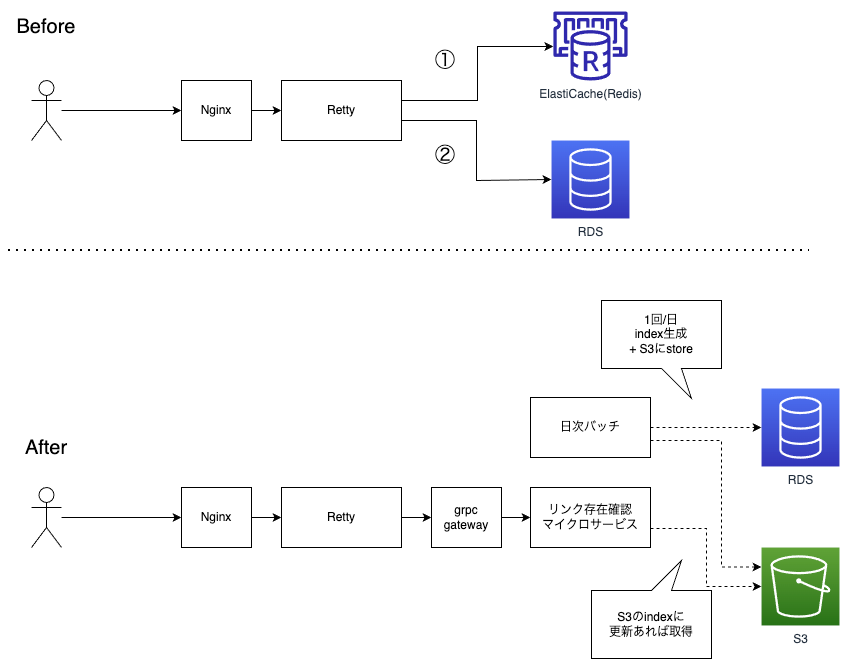
構成のBefore/After
今回の対応完了後は、下記の構成となりました。
本記事と関連しない詳細は省略しています。
- Before: (1)RettyからElastiCache(Redis)に問い合わせ、(2)キャッシュがなければDBに存在確認クエリ発行
- After
- Rettyからは存在確認サービスに問い合わせる
- またバッチ処理として、日次で検索用indexを作成
背景
まとめページと存在確認
今回改修対象としたのは、Rettyのまとめページのリンク存在確認です。
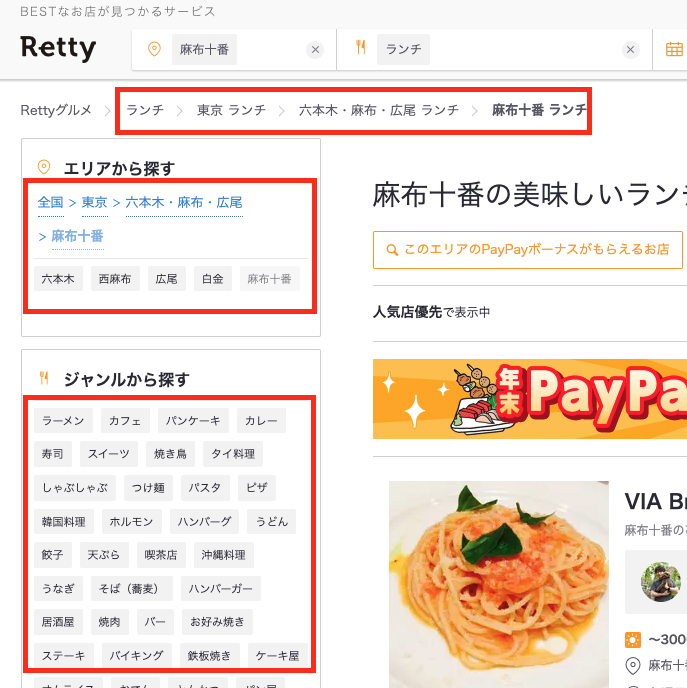
Rettyでは、お店に紐づくカテゴリなどの情報に基づき、動的にページのコンテンツ(お店)が増減しますので、ページ表示時にリンクが本当に存在するか確認する必要があります。
これを行わない場合はページ上に404のリンクが表示されてしまったり、出るべきリンクが出ないことが起こりえます。
しかしRettyでは、このリンク存在確認の負荷が大きく、DB利用時間の約半分を占めていました。
キャッシュレイヤを追加したり、定期的にキャッシュを生成してくれるワーカーを作ったりと対応を重ねていましたが、
現状の対応では改善できる範囲に限界があったため、存在確認の仕組みを刷新することになりました。
なぜリンク存在確認がボトルネックだったのか
リンクの存在確認をする処理ですが、どこに負荷要因があるかというと、
- 1度のページ閲覧(PV)あたりの発行クエリ数が多く、平均的に数百クエリ/PVが発行される
- SEOの歴史的背景より、内部リンクそのものが多い
- 十分な数のリンクを表示できるようにするため、表示されるリンクよりも多くのリンクを候補としている
- キャッシュの有効期限を長くはできない
- ページに掲載されるコンテンツ(お店)の数が日々増減するため
- 対象のページ数が膨大である
- Rettyまとめページは複数の条件(エリア・カテゴリ・目的など)の組み合わせから成っており、非常に多くのページが存在する
- 短い有効期限でキャッシュが切れ、その対象が多いのでDBに直接発行されるクエリ量は大きくなる
という状況でした。
取り組み内容
本プロジェクトは以下のように進みました。
私が加わったのが3.の移行タイミングのため、それまでの経緯の詳細は割愛させていただきます。
1. 対象領域の選定
こちらは昔から計測・認知はされており、DB負荷の約半分がこの存在確認クエリによるものであり、改善の余地が大きいため対象領域となりました。
2. 根本対応方針の決定と実施
これまでDBに対して存在確認のクエリを発行していましたが、これは下記のようなものでした。
- ページに表示されるお店の数を算出する
- 表示される条件とは、ページの要素(エリア・カテゴリ・目的など)にお店が合致しているかどうか
例えば、「新宿 カフェ ランチ」に一致するお店は何件か、という感じです。
これはいわば集合演算に相当します。
「新宿のお店の集合」「カフェのお店の集合」「ランチのお店の集合」の積集合を取ったものが、上記例の結果となります。
Rettyでは、検索対象となるキーワード(新宿・ランチなど)は予め用意されているため、集合を事前に構築しておくことができます。
また、今回はあくまでお店の数を出せれば良いので、集合の一覧が数GBのメモリに乗るサイズとなりました。
そのため、RDBである必要がなく、今回はRustのHashSetを利用したマイクロサービスを構築するに至りました1。
サービスはindex作成バッチとWebアプリケーションの2つから構成されていて、
- バッチ: 日時バッチでindex(RustのHashSet)を生成しS3に保存する
- Webアプリケーション: S3からindexを読み込み、それをもとに集合演算をするgRPCを提供する
となっています。
こちらについては、作成後にRettyのマイクロサービス群の一部となり、 マイクロサービス移行されたページについてはこちらの存在確認サービスを利用するようになりました。
軽くRettyのマイクロサービス事情について触れておくと、
現在Rettyはマイクロサービス化を進めており、ページによっては完全にマイクロサービスに切り替わったものもあります。
Rettyのマイクロサービス事情詳細はこちらを御覧ください: https://engineer.retty.me/entry/2021/06/04/110000
移行されていない機能については、旧環境であるモノリスサービスを引き続き利用しています。
3. モノリスサービスでの移行
新しいサービスについてはマイクロサービスとして動作し始めたものの、
存在確認トラフィックのほとんどは、マイクロサービス移行前のモノリスサービス上で動作しておりました。
そのため、モノリスサービス上から存在確認サービスを呼ぶように移行作業をする必要がありました。
そのために実施した内容は下記です。
- モノリスサービスにおける変更必要箇所の調査
- マイクロサービスの動作検証と修正
- 本番投入されてはいたものの、表出していたのは一部であったため、表出していない部分については検証と修正が必要だった
- grpc-gatewayサービスの作成
- モノリスサービスが諸事情によりgRPCを呼べないため追加
- 段階的リリース
- トラフィックが多いため、一部ページから徐々にリリース対象ページを拡大
こちらの移行作業については、作業範囲が広範に渡ることから、バックエンドエンジニア3人(うち1人は私)、インフラエンジニア1人の4人チームで対応しました。
対応期間としては、9月頭〜11月初めの2ヶ月強でした。
苦労やトラブルとその対応
ここでは、主に「3. モノリスサービスでの移行」についての苦労とトラブル、そして行った対処を紹介します。
ページの種類が多いため、検証対象が多い
Rettyでは過去の施策より、数多くのページが生成されてきました。
まとめページの検索に用いられるパラメータとしてエリア・カテゴリ・目的などがあると述べましたが、それらにも区分があり、例えばエリアであれば県や市区町村、駅などの区分があります。
これらのパラメータが組み合わされ、かつパラメータによっては過去施策による分岐もあったため、検証対象となるページ種類でいうと100種類弱ありました。
さらに、リンク存在確認ではミスがあっても偶然一致してしまう可能性は高いので、今回は2,000ページを対象としてチェックすることにしました。
非常に検証対象が多かったのですが、リンク有無という機械的判定が可能な対象なので、自動検証ツールを初期に構築して検証コストを下げました。
自動検証ツール: 対象ページをクロールしてデータ収集し、バックエンドを新旧存在確認で差し替えて比較
本検証ツールのおかげで多くの時間を節約できました。
過去の施策によりロジックが複雑化していた
Rettyのまとめページですが、10年近く前から手が加えられ続けており、過去の様々な施策の残骸が残っています。
今回の対象でいうと例えば、
- 一部のエリアだけ別のテーブルを参照する分岐があるクエリ
- 特定のカテゴリに合致する場合リンクが作られない
があり、かつこれが一つの巨大なクエリ構築関数で作られていたため、追っていくのに苦労しました。
これに対しては、今回の検証対象ページにおけるクエリをすべて収集して分類し、テスト結果と異なるページについて旧ロジック(SQL)と新ロジックとを比較する助けとしました。
旧環境の仕様を完全に把握できる人がいない
長い歴史のページであることと、コードベースが大きい(関連コード合わせると数万行)こと、直近だとマイクロサービス開発がメインであることから、旧環境の特に存在確認周りの仕様を完全に把握している人はいませんでした。
また、初期は特にissueやPRコメントも充実しておらず、実装背景調査に苦戦することがありました。
ただ、直近でドキュメント作成の動きが全社的に盛んになり該当コード周辺の調査ログが残っていたこと、何人かは当時の事情にも詳しい方からアドバイスいただけたことが幸いし、進めていくことができました。
一度はリリース直後にマイクロサービスがダウンして失敗
今回のリリース後の「モノリスサービス => 存在確認サービス」のトラフィックですが、Rettyの約半分を占めるページが対象であること、さらにページあたり数百リクエストが飛んでくることから、非常に大きくなることが予想されました。
そのため、リリースは徐々に対象ページを拡大することで、リスクを抑えて実施できるように計画しました。
段階は4つあり、0.1% => 1% => 10% => 100%とトラフィックが増加するようにしました。
4段階中3段階は問題なくリリースでき、最終リリースもサーバーリソースなど準備をして臨んだのですが、最終リリースではマイクロサービスが負荷でダウンし、オートスケールも正常に働かなかったため、あえなくロールバックしました。
その後メトリクスを調査してみたところ、
- 存在確認サービスに対する負荷分散ができていなかった
- grpc-gatewayがコネクションをkeepするため、それを考慮できていなかった
- 参考: https://christina04.hatenablog.com/entry/grpc-keepalive
- 得られていたメトリクスが一部間違っており、適切なリソース準備ができていなかった
ということがわかりました。
また、本番想定の負荷試験ができていなかったことも原因の一つではあります。
そのため、その後問題の修正・本番想定の負荷試験をした後、再度無事リリースされました。
まとめ
本プロジェクトでは、成果としてDB・Redisの負荷を大きく削減することができました。
実施内容としては、DBの負荷を存在確認マイクロサービスに移すことでした。
旧ロジックを廃止して存在確認マイクロサービスを利用する際の移行の苦労について書きました。
次のステップとして、DB(RDS)サイズの削減やRedisの統廃合によるコストダウンが行われています。
-
私が参加する前には構築完了していました↩