この記事は、Retty Part1 Advent Calendar 2021の18日目の記事です。 adventar.org
こんにちは!RettyOrderの開発リーダーをしている諏訪です。早いもので、アドベントカレンダー書いているともう今年も終わりなんだなぁという気持ちになってきます。
さて、先月Go Conference 2021 Autumnで「GoとGraphQLを使用したサービス開発」というタイトルでRettyOrderの開発の話をしてきました。
※見逃した方はこちらにアーカイブが残っています。 gocon.jp
この発表でAPM周り気になるとのお声をいただいたので、本記事ではgqlgenとAPMのところについて掘り下げていきたいと思います。↑で前提とかの話はしているのでその辺の話は飛ばします。
gqlgenのフック
gqlgenでは HandlerExtension というものを *handler.Server に渡してあげるといろんなイベントにフックを仕掛けることができます。gqlgenが実装しているapq(Automatic persisted queries)などもこの仕組みを使って実装されています。
ここで仕掛けられるイベントに以下の二つのイベントがあります


コメントに記載されているようにそれぞれ、
- 各オペレーションの実行時
- 各Fieldの評価時
にこれらのフックが実行されます。(他にも仕掛けられるイベントはあるのでこちらをみてみてください)
具体的には以下のように呼ばれることになります。
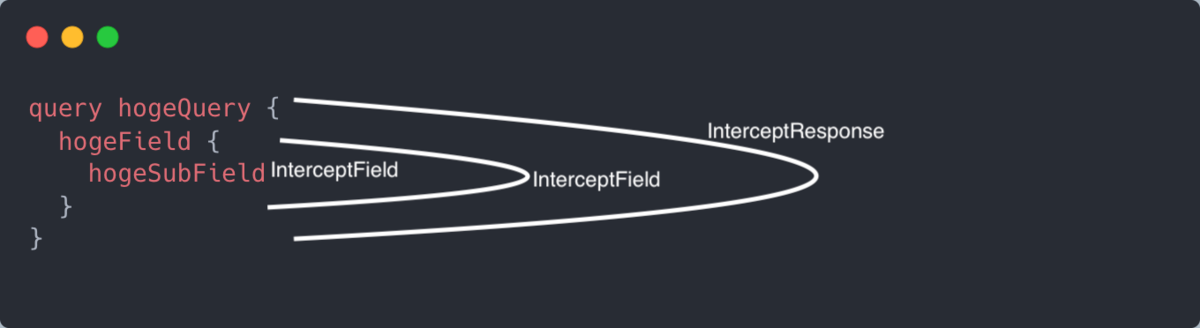
これを利用することでどのクエリのどのフィールドの評価に時間がかかっているか(またその先のどの処理が重いのか)を取ることができます。
実装
先の二つのイベントを利用した最小の実装はこのようになります。これをベースに実装を追加していきましょう
package middlewares import ( "context" "github.com/99designs/gqlgen/graphql" ) type graphqlTracer struct{} var _ interface { graphql.HandlerExtension graphql.ResponseInterceptor graphql.FieldInterceptor } = &graphqlTracer{} func NewGraphQLTracer() graphql.HandlerExtension { return &graphqlTracer{} } func (t graphqlTracer) ExtensionName() string { return "GraphQLTracer" } func (t graphqlTracer) Validate(_ graphql.ExecutableSchema) error { return nil } func (t graphqlTracer) InterceptResponse( ctx context.Context, next graphql.ResponseHandler, ) *graphql.Response { return next(ctx) } func (t graphqlTracer) InterceptField( ctx context.Context, next graphql.Resolver, ) (interface{}, error) { return next(ctx) }
まずInterceptResponseですが、ここで最低限欲しいのは
- どういうクエリなのか
- どういう変数が渡されたのか
が欲しいです。クエリが分かればどういうデータを取得しようとしているのか、変数が分かれば特定のIDのときだけ重いんじゃないかなどがわかるようになります。またこの二つが分かれば手元で再現させることもできます。 あとOperationNameも取っておくとクライアントのどのクエリなのかが簡単に識別できたりします。
※セッショントークンなどセンシティブなデータは送らないように気をつけてください
それぞれのデータはgqlgenがcontextに埋め込んでくれていて、GetOperationContext() を利用すると引き出せます。
func (t graphqlTracer) InterceptResponse( ctx context.Context, next graphql.ResponseHandler, ) *graphql.Response { rc := graphql.GetOperationContext(ctx) span, sctx := tracer.StartSpanFromContext( ctx, "graphql.request", tracer.ServiceName(t.serviceName), tracer.ResourceName(rc.OperationName), tracer.Tag("graphql.operation.name", rc.OperationName), tracer.Tag("graphql.query", rc.RawQuery), tracer.Tag("graphql.variables", rc.Variables), ) res := next(sctx) if res == nil { span.Finish() return res } if res.Errors != nil { span.Finish(tracer.WithError(err)) } else { span.Finish() } return res }
弊社ではDatadogを利用しているのでこのようにSpanに埋め込んでいます。
ここでのポイントはStartSpanFromContextで取得したcontextをnextに渡している部分です。元のcontextではなくここで生成したcontextを次に引回すことで次のFieldの評価時にOperationとの親子関係を作ることができます。
次にInterceptFieldですが、ここでは
- どのFieldなのか
- どのObjectなのか
が必要です。Objectまで取っているのは例えばidというといろんな型がidを持っていると思うので、どの型のFieldなのかを識別するために必要です。
Fieldの場合もデータをcontextに埋め込んてくれているので GetFieldContext()を利用して取り出しましょう。
func (t graphqlTracer) InterceptField( ctx context.Context, next graphql.Resolver, ) (interface{}, error) { fc := graphql.GetFieldContext(ctx) span, sctx := tracer.StartSpanFromContext( ctx, "graphql.field", tracer.ServiceName(t.serviceName), tracer.ResourceName(fc.Field.ObjectDefinition.Name+"."+fc.Field.Name), tracer.Tag("graphql.field.name", fc.Field.Name), tracer.Tag("graphql.field.type", fc.Field.ObjectDefinition.Name), ) res, err := next(sctx) if err != nil { span.Finish(tracer.WithError(err)) } else { span.Finish() } return res, err }
これでデータが取れるようになりました。このままでもいいのですが、これには一つ課題があります。
type HogeEntity { id: ID! name: String! fuga: FugaEntity! # use Resolver calculatedXXX: String! # use Resolver } type FugaEntity { id: ID! name: String! }
例えばこのような定義があったとします。Resolverの定義がないHogeEntityのidとname, FugaEntityのidとnameはそれぞれHogeEntity,FugaEntityが評価された時点でデータが取れるのでこれらのSpanはなくてもいいです。APMでみたいのはどのFieldが評価されたのかではなく、どのResolverの処理に時間がかかったのかを見たいです。
Resolverかどうかの判定はGetFieldContextで取れた構造体にIsResolverが定義されているので、これを使ってResolverではない場合はTraceをスキップしてしまいましょう。
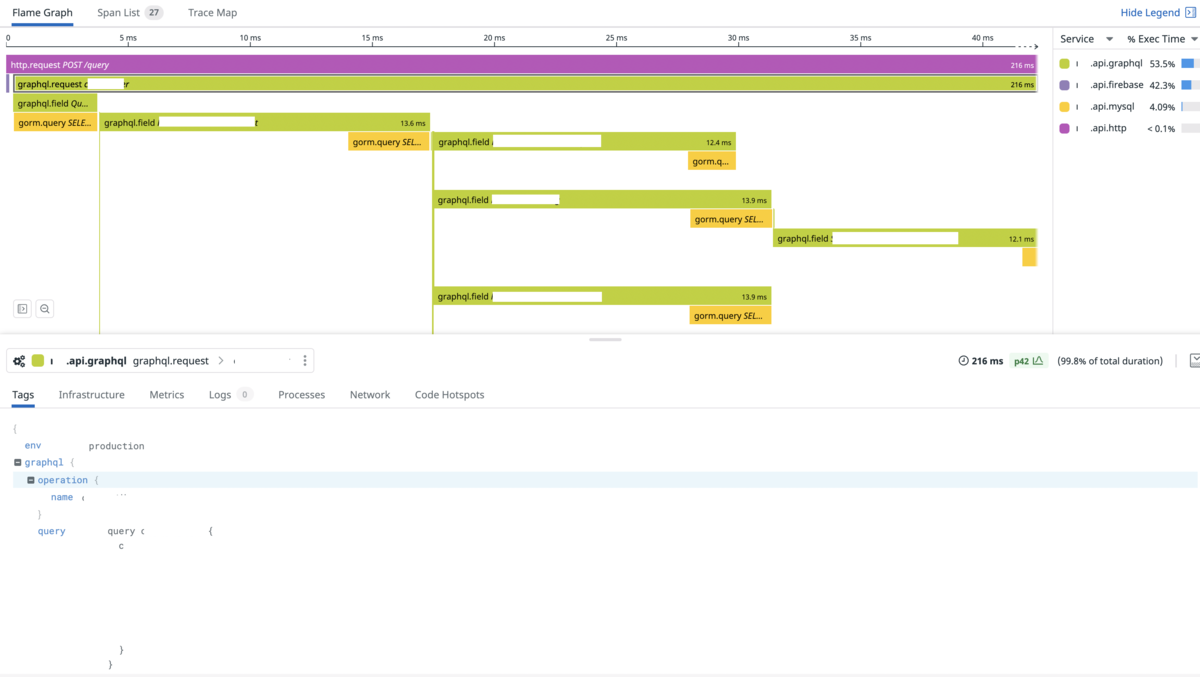
ここまで実装するとどういう順序で処理されてどこに時間がかかっているのかが分かりやすいグラフを作ることができます。
まとめ
APMがあるとパフォーマンス向上や障害が起きたときの切り分けなど運用がしやすくなります。 運用しやすい=ユーザーさんに価値を届ける開発に集中できることにもつながるので、運用しやすい環境を作っていきましょう!