(本記事はRettyアドベントカレンダー2020 8日目の記事です) adventar.org
昨日は、森田くんによる「FDP APIサーバーの成長報告」でした!
はじめに
こんにちは、Retty広告コンテンツ部開発チームでエンジニアをしている佐藤です。 最近すき焼きにハマっており、ふるさと納税の返礼品のお肉で、すき焼きざんまいの食生活を送っております。 締めのうどんがドロドロしてこれがめちゃくちゃ美味しいのです。。。
前置きは以上で、今回の記事ではAWS Batchの環境構築からバッチ処理を実行するまでの流れについて備忘録も兼ねて、記事にしたいと思います。
使う機能
- Amazon EC2
- Amazon ECS
- AWS Batch
- Amazon CloudWatch
先日(12/03)AWS BatchのコンピューティングリソースにEC2だけでなく、AWS Fargateも使えるようになったらしいです
実行までの流れ
AWS Batchにジョブを送信するとEC2インスタンスを起動して、ECRまたはDocker Hubからコンテナイメージを取得しタスクを実行してくれます。 →処理が完了したらインスタンスを削除してくれます。
基本的には上記の繰り返しになります。
環境構築と実行
基本的にAWSのドキュメントに従えば問題ないと思います。 GUIでポチポチするだけで環境構築ができるのは分かりやすくて良いですよね。 、、、とは思いつつ何度も同じ操作をすることは面倒くさいので、ここからはGUIではなくコマンドで環境構築をおこなっていきます。
コマンドの実行に使う環境変数の設定
AWS Batchの環境構築に必要な環境変数をあらかじめ設定しておきます。 私の場合の例なので、このあたりはよしなに変更してください。
$ export AWS_ACCOUNTID=25254649 $ export AWS_REGION=ap-northeast-1 $ export SUBNET1=subnet-2525 $ export SECURITYGROUPID=sg-2525 $ export DOCKER_IMAGE=busybox
コンピューティング環境の作成
$ \
SERVICEROLE="arn:aws:iam::${AWS_ACCOUNTID}:role/service-role/AWSBatchServiceRole"
INSTANCEROLE="arn:aws:iam::${AWS_ACCOUNTID}:instance-profile/ecsInstanceRole"
cat << EOF > compute-environment.spec.json
{
"computeEnvironmentName": "test",
"type": "MANAGED",
"state": "ENABLED",
"computeResources": {
"type": "EC2",
"minvCpus": 0,
"maxvCpus": 4,
"desiredvCpus": 0,
"instanceTypes": ["optimal"],
"subnets": ["${SUBNET1}"],
"securityGroupIds": ["${SECURITYGROUPID}"],
"instanceRole": "${INSTANCEROLE}",
"ec2KeyPair": "test"
},
"serviceRole": "${SERVICEROLE}"
}
EOF
aws batch create-compute-environment --cli-input-json file://compute-environment.spec.json
上記のコマンドでtestという名前でコンピューティング環境が作成されます。

ジョブキューの作成
$ \
COMPUTE_ENV_ARN="arn:aws:batch:${AWS_REGION}:${AWS_ACCOUNTID}:compute-environment/test"
aws batch create-job-queue \
--job-queue-name test-queue \
--priority 1 \
--compute-environment-order order=1,computeEnvironment=${COMPUTE_ENV_ARN} \
> create-job-queue.log
上記のコマンドでtest-queueという名前でジョブキューが作成されます。

ジョブの定義
$ \
cat << EOF > job-definition.spec.1.json
{
"image": "${DOCKER_IMAGE}",
"command": ["echo", "hello"],
"vcpus": 2,
"memory": 30000
}
EOF
aws batch register-job-definition \
--job-definition-name test-job-definition \
--type container \
--container-properties file://job-definition.spec.1.json \
> register-job-definition.log
上記のコマンドでtest-job-definitionという名前でジョブ定義が作成されます。
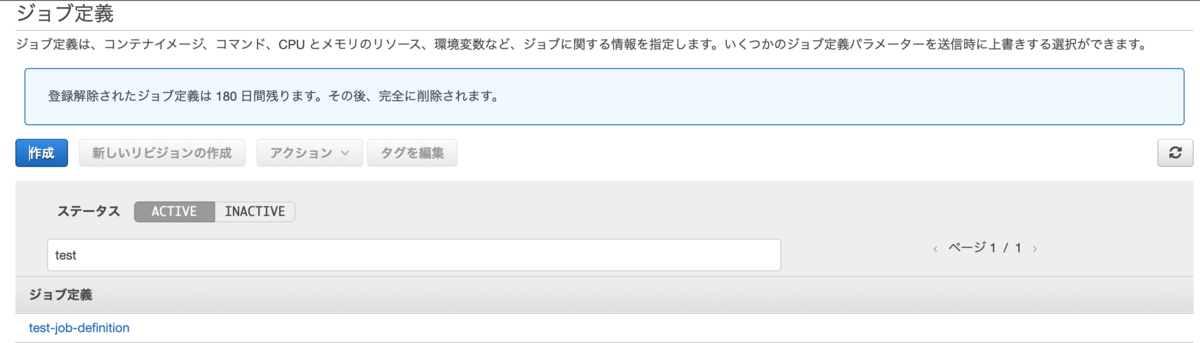
お疲れさまでした!
以上で一通りの環境構築は終わったので、タスクを実行していきましょう。
BatchでHello World
まずは多くのプログラミング言語入門書などで最初の例として挙げられている「Hello World」に習って、AWS Batchでもやってみます。 この後で、 「Hello World」のそれぞれの文字をあるタスクの1単位と見立てて依存関係を持たせて実行してみます。
$ aws batch submit-job \
--job-name test \
--job-definition test-job-definition \
--container-overrides '{
"command": ["echo", "Hello World"],
"memory": 2000
}' \
--job-queue "arn:aws:batch:ap-northeast-1:'$AWS_ACCOUNTID':job-queue/test-queue"

上記のように出力されました。
依存関係を持ったジョブの実行
ここまでが前座です。 ここからはタイトルの通り依存関係を持ったバッチ処理を行うための方法です。
長くなってしまったのでシェルスクリプトを用意しました。
#!/bin/bash
set -e
# 実行するジョブの名前を定義
h="h"
e="e"
l="l"
o="o"
w="w"
r="r"
d="d"
# 最新のジョブ定義取得
## ジョブ定義を更新する毎にRevisionがインクリメントされるため
JOB_DEFINITION_ARN=$( aws batch describe-job-definitions \
--job-definition-name test-job-definition \
--status ACTIVE \
| jq -r '.jobDefinitions | max_by(.revision).jobDefinitionArn' \
)
# ジョブキューを定義
JOB_QUEUE1="arn:aws:batch:ap-northeast-1:'$AWS_ACCOUNTID':job-queue/test-queue"
submit_job() {
if [ -z "$5" ]; then # 依存関係がない場合
depends_on_clause=""
else
depends_on_clause="--depends-on jobId=$5"
fi
JOB_INFO=$( aws batch submit-job \
--job-name $1 \
--job-definition ${JOB_DEFINITION_ARN} \
--container-overrides '{
"command": ["echo", "'$2'"],
"memory": '$3'
}' \
--job-queue $4 \
$depends_on_clause
)
}
# h
submit_job ${h} "h" 20000 ${JOB_QUEUE1}
FIRST_JOB_ID=$(echo ${JOB_INFO} | jq -r '.jobId')
# e
submit_job ${e} "e" 30000 ${JOB_QUEUE1} ${FIRST_JOB_ID}
SECOND_JOB_ID=$(echo ${JOB_INFO} | jq -r '.jobId')
# l
submit_job ${l} "l" 30000 ${JOB_QUEUE1} ${SECOND_JOB_ID}
THIRD_JOB_ID=$(echo ${JOB_INFO} | jq -r '.jobId')
# l
submit_job ${l} "l" 30000 ${JOB_QUEUE1} ${THIRD_JOB_ID}
FOUR_JOB_ID=$(echo ${JOB_INFO} | jq -r '.jobId')
# o
submit_job ${o} "o" 30000 ${JOB_QUEUE1} ${FOUR_JOB_ID}
FIVE_JOB_ID=$(echo ${JOB_INFO} | jq -r '.jobId')
# w
submit_job ${w} "w" 30000 ${JOB_QUEUE1} ${FIVE_JOB_ID}
SIX_JOB_ID=$(echo ${JOB_INFO} | jq -r '.jobId')
# o
submit_job ${o} "o" 30000 ${JOB_QUEUE1} ${SIX_JOB_ID}
SEVEN_JOB_ID=$(echo ${JOB_INFO} | jq -r '.jobId')
# r
submit_job ${r} "r" 20000 ${JOB_QUEUE1} ${SEVEN_JOB_ID}
EIGHT_JOB_ID=$(echo ${JOB_INFO} | jq -r '.jobId')
# l
submit_job ${l} "l" 30000 ${JOB_QUEUE1} ${EIGHT_JOB_ID}
NINE_JOB_ID=$(echo ${JOB_INFO} | jq -r '.jobId')
# d
submit_job ${d} "d" 30000 ${JOB_QUEUE1} ${NINE_JOB_ID}
上記スクリプトの実行結果になります。
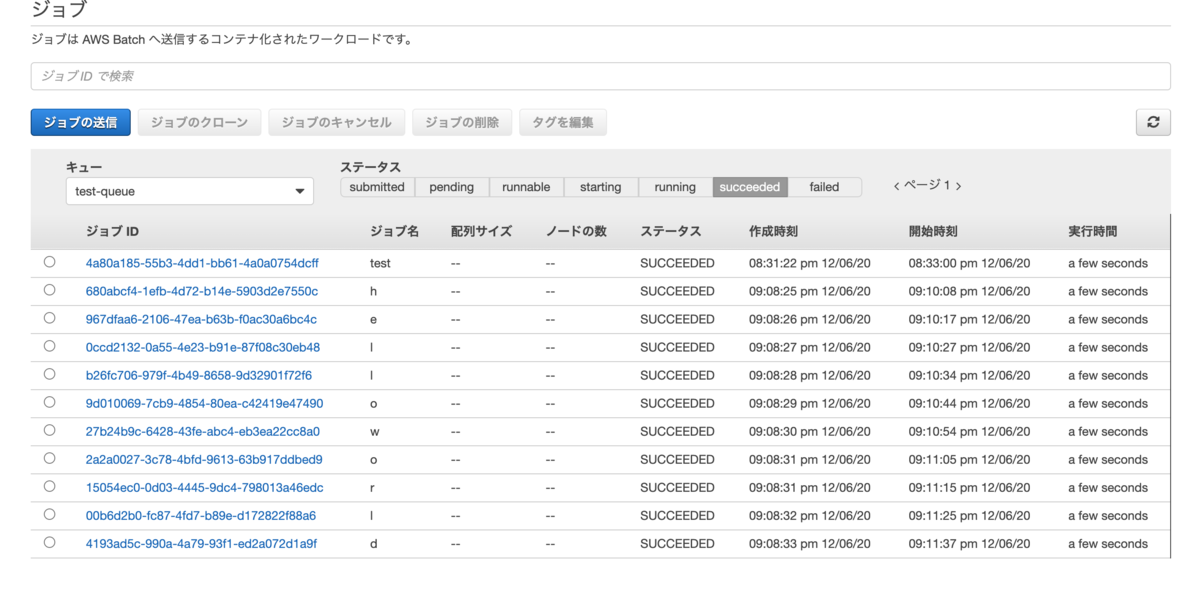 ちゃんと定義した順番通りに実行されたことがわかります。
ちゃんと定義した順番通りに実行されたことがわかります。
最後に
今回は文字列を出力するだけでしたが、AWS BatchはECRのDockerイメージを使用したり、EFS利用することでインスタンス終了時にもタスク生成物を残すことができたり、様々なサービスを柔軟に組み合わせて処理を行うことができます。 なにかの参考になれば嬉しいです。
明日である10日目は 広告コンテンツ部開発チームのマネージャーである進藤さんの記事です!