Original article (日本語): http://qiita.com/taru0216/items/dda1f9f11397f811e98a
Retty “How to make a machine learning infrastructure that supports 22 million users”

Hello, everyone. My name is Taruishi, and I’m the CTO at Retty.
There’s not much time left until the year is over. Have you already decided how you’ll spend the rest of the year?
The number of engineers at Retty have nearly doubled in the past year. As a result, we have enough people to who can write articles which allows us to participate in this year’s Advent Calendar. I’m pleased to see that everyone seems to be having fun doing it.
http://qiita.com/advent-calendar/2016/retty
For the final post for this year’s Retty Advent Calendar I had considered writing about what I did over this past year at Retty, but that’s not very unique or interesting. Instead, I decided to write about something fairly crazy that I did this year.
That is, “Building Retty’s machine learning infrastructure using parts purchased while walking around Akihabara”.
※ This is not a post about machine learning techniques or history. If that’s what you’re looking for, then I recommend checking out Rakuten Institute of Technology’s Mori’s Advent Calendar (日本語) or check out this summary (日本語) and start reading from there.
※ This post has a lot of logos and images to make it easier to read. The names of all software, products, companies, stores, and their logos, are copyrighted by their respective owners.
※ This article was written with the intent of being as accurate as possible, but no guarantees can be made.
Overview of Retty’s machine learning infrastructure system architecture
First, I would like to explain the architecture of Retty’s machine learning infrastructure.
We have 5 ATX-sized machines running on Intel processors, all equipped with 2 consumer-grade NVIDIA GPUs.

All machines are running a Docker container with SSH enabled. The GPU can be used by logging into any of the machines. The home directory of the Docker container is shared through NFS so you have access to the same data no matter what machine you are using.
From the machine learning engineer’s point of view, all 10 GPUs are part of a “preemptible container1 where you can access the same files no matter where you are logged in”.

Examples of techniques developed using Retty’s machine learning infrastructure
I’d like to introduce some of the stuff that has been developed using Retty’s machine learning infrastructure now.
Image Categorization
A classic machine learning problem. At Retty, we separate images into 4 different categories: “food”, “restaurant exterior”, “restaurant interior”, and “menu”.

Source: https://retty.me/area/PRE13/ARE14/SUB1401/100001178822/photos/ (日本語)
This was all done manually until we were able to come up with a CNN model that produced results accurate enough for us to be able to put it into production.
Tagging Food Pictures
Using image categorization, we were able to create techniques to tag what kind of food is displayed in a picture. As you can see below, the image tagged “pancake” is automatically being chosen to represent the restaurant in the search results.
Before
Search keyword: Pancake

After
Search keyword: Pancake

Source: https://retty.me/area/PRE01/ARE164/LCAT9/CAT161/ (日本語)
Previously only one pre-selected image would be displayed to represent the restaurant in the search results. But, using the above “Omurice and Pancakes” restaurant as an example, some restaurants are known for more than just one type of food. In this case, since the omurice picture would normally be displayed, users searching for pancakes would end up seeing omurice instead.
Using the image tagging technique, we are now able to show omurice to people searching for omurice, and pancakes to users who are searching for pancakes.
Super Resolution (Making images clearer)
Super resolution is the process of making an image a higher resolution and then converting it into an even clearer picture.
Up until recently it was common to filter the image based on edge enhancement, but in recent years it’s there has been great development of techniques using deep learning to create super resolution images.
We also tried our hand at using deep learning to create super resolution images here at Retty.

(Image from restaurant: https://retty.me/area/PRE13/ARE1/SUB101/100000868744/ (日本語))
It might be difficult to tell the difference between the two methods from just the side by side embedded image, so let’s take a closer look.


※ This technique could possibly be used to improve the compression ratio of lossy images. I think it’s worth keeping an eye on.
In addition, we’ve had several people develop about 30 new techniques to solve such problems as extracting unique characteristics about a restaurant based on user reviews (日本語) and detecting high quality images that look like they were taken with a DSLR camera (日本語). When I say new techniques, I mostly mean it in the way that that it takes our company some time to get caught up with all of the new papers coming out.
Machine learning web apps have also been developed to make it easier for non-machine learning engineers to take advantage of the new techniques.

They are lovingly known as ICACHAN (for image classification), MICANCNN (for image modification), and TACOCNN (for natural language processing).



6 reasons we built the machine learning infrastructure ourselves
Retty has run its service on AWS from launch all the way up until last year. Starting with this year, we have started using other cloud services such as Google’s BigQuery and Microsoft’s Azure, but we hadn’t attempted anything outside of the cloud.
There are reasons why I decided that it was a good idea for Retty to build its own infrastructure with parts we bought ourselves.
- A GPU is required for deep learning
- Our deep learning engineers had sticker shock after seeing the price of cloud instances with GPUs
- Since there was little information available about the efficiency of the GPUs, it was hard to tell how much it would cost to use for machine learning
- Our engineers got too caught up in trying to figure out what instance would perform the best for a given algorithm based various bottlenecks that may be present such as CPU, GPU, memory, IO, or network, which meant less time spent working on the actual machine learning tasks
- Since we would be SSHing into the machines for development work, the latency between the cloud service and our office did not help with productivity
- Since the price of GPUs get cheaper by the month, I thought maybe it would be possible to build a low cost system by buying only the parts required at the time they were needed
There were various reasons why I chose to build our own system in addition to those already listed above, but if I had to choose one reason in particular, it would be that we wanted to create an environment that the engineers could freely use at any moment. Now, with the creation of our own system, there is always at least 1 person using the GPUs at any given time of the day.
How the machine learning infrastructure was implemented
When designing our system, requirements for future development had to be taken into consideration.
- A system that could easily be improved and scale to the current demands
- The data and environment should be prepared in such a way that machine learning tasks can be started immediately without issue
- When the machines are reinstalled each iteration, the engineers’ data should still remain untouched
- In order to get the best return on our investment and increase the amount of techniques available to us, another goal was to use the cheapest parts and to use open source software and techniques
After iterating through PDCA many times, our architecture ended up looking like this.

- juju for configuration management
- MaaS for automatic OS deployment and AWS spot instancing
- ceph for distributed storage system
- corosync/pacemaker for the NFS cluster
- A Docker image including all software required for machine learning
- Kubernetes for VXLAN management and Docker container scheduling
juju for configuration management

juju is an infrastructure configuration management tool. There are other similar tools out there like Ansible, Chef, and Puppet. juju is available as a standard tool within Ubuntu and can be instance bootstrapped which works very well with the previously mentioned MaaS software, and is also easy to scale. For example, you can add 48 machine learning machines using the following command2:
juju add-unit -n48 akiba
※This is just my personal opinion, but I think that juju is much more easier to use than other similar tools. The approach in regards to ease of use might just be the way of Debian-based distributions, similar to apt.
Retty’s machine learning infrastructure makes heavy use of Docker (Kubernetes). Since a large majority of the management is being done through Docker, juju is being used when creating the Docker (Kubernetes) environment.
MaaS for automatic OS deployment and AWS spot instancing

MaaS is an OS deployment system that is capable of automatically installing an OS from a bare metal environment. Using PXE booting, it’s possible to automatically install Ubuntu on top of the bare hardware. It a fully featured system that has other features such as software RAID and bonding. We use MaaS on our custom built machine learning cluster.
juju can also be used with not just MaaS, but also cloud services such as AWS, Azure, and GCP. When more GPU power is required than is available within our cluster, we scale using the cloud’s spot resource3.
ceph for distributed storage system

ceph is a distributed storage system that allows for one virtual storage system over the network to be used across multiple servers. A common use for ceph is as a distributed block device, which is also how we’re using it in the Retty machine learning infrastructure.
(We’ve also started using the recently released stable version of cephfs lately.)
corosync/pacemaker for the NFS cluster

Source: http://clusterlabs.org/
In order to create a NFS server that does remains running during machine maintenance, ceph acts as the block device while corosync and pacemaker are used to create a single master and failover NFS server.
A Docker image including all software required for machine learning

In addition to tensorflow and chainer, we require other libraries like genism, mecab (日本語), cabocha (日本語), word2vec, fastText, keras, etc. To ease the pain of having to install all of the required libraries, we’ve created a Docker image that can automatically install everything. As long as NVIDIA drivers are installed on the host machine, you can run a command such as
docker run --privileged -it --rm 192.168.0.1/retty-runtime-anaconda
and it will set up a machine learning environment just like that. Since the Docker image is 10gb (5gb compressed), we use a Private Docker Registry on our servers and pull the image directly from there. What used to take about 70 minutes to complete now takes a mere 5 minutes.
(Since the machine learning Docker image can also work in a CPU-only environment, it’s possible to do this all from a Mac as well.)
Kubernetes for VXLAN management and Docker container scheduling

Kubernetes uses the SSH-enabled Docker images to run on each individual machine. It is running through a simple VXLAN virtual network created with flannel. Home Docker is running on all of the host machines, so the machine learning engineers are able to log into any machine. The home directory is setup using the previously mentioned NFS server with failover enabled. This setup allows the engineers to have the same files no matter what machine they are using at the time.
There is also Docker running within Kubernetes. This allows the machine learning engineers to easily run simple Docker features through the command line, such as docker-compose.
The techniques behind the Retty machine learning infrastructure
In order to increase performance and productivity, various techniques are in place for the Retty machine learning infrastructure.
Disk Performance
All machines have 6 separate SSDs, bringing us to a total of 30 SSDs being used to create a distributed storage system. Using iotop to measure performance and ceph to rebalance the data (data management), 1 node can reach a max throughput of up to 450 MB/s (3.6Gbps). I think there’s still more room for improvement, but for now it’s good enough for our purposes.
I should also point out that the motherboard that we use in our machines (z170 chipset) has only 6 SATA ports. Since all 6 ports are dedicated to ceph, the systems are booted using an SSD connected using a SATA to USB adapter. Therefore, there are 7 drives used per 1 node. The reasoning for this is to make better use of ceph’s block device, and also because we had the need to add more disk space.
Network Performance
In addition to the internal ethernet board we are bonding 3 dual port gigabit ethernet PCIe devices. We originally wanted to use a cheap fanless L2 switch, so we use Adaptive Load Balancing instead of link aggregation to distribute traffic.

There are a lot more ethernet cables than there are machines, as you can see from the above picture.
GPU Benchmarks
Since we are in possession of various GPUs that can run tensorflow and chainer, we took benchmarks throughout development. We had a few cards that ran on the Maxwell architecture (GTX 750ti, 970, 980ti) and a majority of the cards that ran on the Pascal architecture (GTX 1050ti, 1060, 1070, 1080). What we found out is that the performance, power efficiency, and cost performance of each card changed depending on the algorithm being used.
Here are some of our findings. This data was collected at varying points in time which unfortunately means we weren’t able to measure performance within the same environments, so it’s a little difficult to draw direct comparisons.
Speed
We measured how many seconds it took to process a given amount of data (the meaning of batch changes per algorithm, so we chose process / sec out of convenience). The results of two algorithms, train.py and char_cnn.py, when run on all available GPUs is shown below. A larger value means more data being processed (better). As expected, the performance increases with more power GPUs. However, there’s an odd case with train.py running much faster on the GTX 980ti.

In comparison, char_cnn.py actually runs slower on the GTX 980ti. At the time of benchmarking, the GTX 980ti was running in a machine with a cheap AMD CPU. We believe that char_cnn.py is a CPU sensitive algorithm which could explain the large difference. One thing that has me scratching my head is that while train.py seemed to have the best performance on the AMD CPU in general, char_cnn.py did not have any real change in performance using the 750ti. We’re recruiting (日本語) anyone who is interested in digging deeper into this mystery.
Energy Efficiency
Next up we measured energy efficiency. Measured as QPS (process / sec) / W.

The Pascal architecture in general had pretty good energy efficiency when compared to the Maxwell’s 970, but the GTX 750ti was a very pleasant surprise considering it does not require any additional power.
Cost Performance
This was calculated based on the price of the GPU as of early October 2016 and the energy consumption subtracted from that price. One yen per iteration. Since the prices of the cards change so much, I don’t think this is a very helpful benchmark.
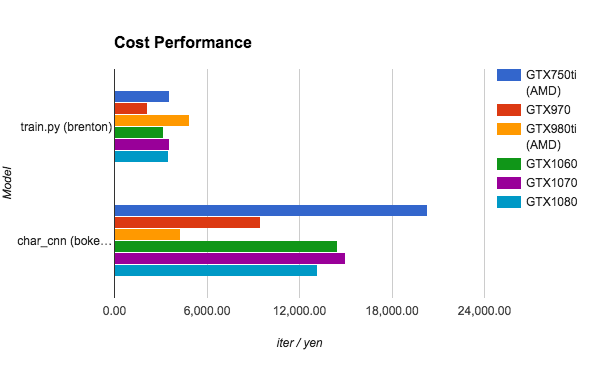

Energy consumption was measured using an off-the-shelf power meter.
Other
One thing that I should note is that the energy efficiency of the Pascal architecture has improved. The Maxwell architecture required a lot of energy, but that problem was fixed with Pascal.
As for the cost performance statistic, it all really depends on the timing of when you calculate the numbers because of how quickly the prices of GPUs can drop. For example, the 980ti dropped in price by half after 5 months.
With the way development of GPUs is currently going, products are going to the outlet bin and dropping prices fairly quickly. That’s why we decided it was best buy little by little in order to mitigate potential loss from fluctuating prices. It makes me wonder how SaaS providers who share GPUs deal with that issue.
And lastly, since our server architecture is mostly decided now, I believe it’s time for us to do some proper benchmarking. There’s functionality in place to scale using the cloud, so it’s possible to compare how consumer grade GPUs do against server grade GPUs as well. If that sounds like something that interests you then please subscribe to the Retty Advent Calendar or come check us out (日本語). You don’t have to be a student either, we’re open to everyone.
http://qiita.com/advent-calendar/2016/ranking/subscriptions/categories/company
Personal Database
Data is required for machine learning. Lots of data. At Retty, we have a massive database consisting of millions of user reviews and even more food-related pictures as well as other related information that we are able to use publicly.
To make it as smooth as possible to experiment with, we thought it would be convenient to use that database as a base for a personal database that you can tweak as you see fit. But, due to the massive size of the database, building such a thing is not an easy task. Restoring an AWS RDS database snapshot for use as a personal database ended up taking almost half a day to finish, which isn’t very realistic for real world purposes.
The Retty machine learning infrastructure takes advantage of ceph’s block device snapshot and cloning functionalities. What took up to half a day, now only took 3 seconds4. That’s roughly 12,000 times faster. To put it into a more conventional comparison, that’s fast enough to escape Earth’s gravity. The world sure has changed5.
Snags along the way
There were issues with our servers crashing completely. The biggest two reasons are as follows.
A DoS attack on CIFS
We were using an cheap off-the-shelf NAS to store images when we first built the machine. NAS was not able to handle all of the requests from the machine learning machine, which caused the CIFS file system kernel module to act up and causing all of the machine learning machines to spit out a Linux kernel oops. Since we couldn’t hook up a monitor to the machine it proved difficult to debug, but we were able to investigate it once we installed kdump. The problem was solved by moving on from CIFS and switching to NFS.
Only 1 network segment
Currently, all of our machine learning servers are hooked up to the same 24 port fanless hub. Sometimes there was just so many broadcast packets that the L2 segment became unresponsive (this happened about 2 times in half a year). At this point 2 times doesn’t seem like a huge deal to us, but it’s something we might fix in the future.
Although it’s not exactly a good thing when looked at from a SPOF point-of-view, including the physical network and power to the office, when the server does happen to go down, we all take advantage of the lunch taxi (日本語) or all-expenses-paid meal (日本語) perks to go out and enjoy a nice meal. You could say that the SPOF helps strengthen communication in a ways, so it’s not completely bad.
Retty’s machine learning infrastructure’s development environment
The infrastructure went through many improvements at the beginning while it was it was being made available to others. There was only one person to make use of it at the beginning and worked reasonably well. Eventually the infrastructure grew into a cluster and another person also started using the systems, which proved difficult to make improvements smoothly. For that reason, a development environment for the machine learning infrastructure itself was born.
This environment uses a virtual machine that can do everything including the automatic OS deployment. It uses VT-d to share the GPU with the specified virtual machines. It’s not possible to use the GPU with just a certain virtual machine which makes this machine restrictive for development that requires GPU usage.
Virtual Machine Creation

We’re using libvirt to handle the management of virtual machines. The biggest plus is that it’s easy to manage virtual machines through the command line, and since it’s made by RedHat it’s able to run well on many Linux distributions.
The virtual machine’s primary disk is running off the machine learning infrastructure’s ceph drive. ceph had problems when installing the virtual machines using the virt-install command, so we added some new code to it.
※ Since virt-install is licensed under GPL, the following patch code is also licensed under GPL
diff -ru /usr/share/virt-manager/virtinst/devicedisk.py /usr/local/share/virt-manager/virtinst/devicedisk.py --- /usr/share/virt-manager/virtinst/devicedisk.py 2015-11-30 20:47:47.000000000 +0000 +++ /usr/local/share/virt-manager/virtinst/devicedisk.py 2016-11-09 05:12:36.513295726 +0000 @@ -464,6 +464,7 @@ "source_volume", "source_pool", "source_protocol", "source_name", "source_host_name", "source_host_port", "source_host_transport", "source_host_socket", + "auth_username", "auth_secret_type", "auth_secret_uuid", "target", "bus", ] @@ -744,6 +745,9 @@ seclabel = XMLChildProperty(Seclabel, relative_xpath="./source") + auth_username = XMLProperty("./auth/@username") + auth_secret_type = XMLProperty("./auth/secret/@type") + auth_secret_uuid = XMLProperty("./auth/secret/@uuid") ################################# # Validation assistance methods # @@ -867,6 +871,12 @@ self._change_backend(None, vol_object, parent_pool) def set_defaults(self, guest): + pool = self._storage_backend.get_parent_pool_xml() + if pool.source_auth_type != "": + self.auth_username = pool.source_auth_username + self.auth_secret_type = pool.source_auth_type + self.auth_secret_uuid = pool.source_auth_secret_uuid + if self.is_cdrom(): self.read_only = True diff -ru /usr/share/virt-manager/virtinst/storage.py /usr/local/share/virt-manager/virtinst/storage.py --- /usr/share/virt-manager/virtinst/storage.py 2015-12-24 16:30:15.000000000 +0000 +++ /usr/local/share/virt-manager/virtinst/storage.py 2016-11-05 04:29:29.270748502 +0000 @@ -380,7 +380,10 @@ "capacity", "allocation", "available", "format", "hosts", "_source_dir", "_source_adapter", "_source_device", - "source_name", "target_path", + "source_name", + "source_auth_type", "source_auth_username", + "source_auth_secret_uuid", + "target_path", "permissions"] @@ -406,6 +409,10 @@ default_cb=_default_source_name, doc=_("Name of the Volume Group")) + source_auth_type = XMLProperty("./source/auth/@type") + source_auth_username = XMLProperty("./source/auth/@username") + source_auth_secret_uuid = XMLProperty("./source/auth/secret/@uuid") + target_path = XMLProperty("./target/path", default_cb=_get_default_target_path)
Using the patch above, it’s possible to specify in the command line arguments a way to allocate the virtual machine’s primary disk on the ceph block device.
virt-install --name=hoge --vcpus=4 --memory=4096 --disk rbd:hoge/fuga ...
Usage as Desktop
This development machine has been turned into a desktop that shows information about the machines. We call it the “Retty Machine Learning Infrastructure Dashboard”. Using the development machine’s GPU, we display the current system information for all of the machines in the infrastructure using a 50 inch 4K monitor.

There’s also an HDMI splitter available that lets engineers have their own view of the dashboard as well.

We thought it would be a waste if that’s all we used it for, though. So the computer has also been turned into a machine that anyone in the office is able to do development directly using the machine or test their own code on it.
This machine has 128GB of memory. It’s also connected directly to all of the machines using a 3Gbps shared bus (3 port ethernet), so it’s acting as if it’s all one machine.
In other words, Retty has a desktop machine with a combined total of 448GB of memory. Since memory is directly related to development capabilities, it’s a good time to be alive. In addition, the 12 GPUs give this desktop machine over 20,000 cores to work with. If this is something you’d like to try out then please check out or post here (日本語).
Summary
Thank you for reading this post.
The Retty machine learning infrastructure has become a desktop machine with 20,000 GPU cores, nearly 500 GB of memory that our engineers can use at any time and scale in the cloud like an amoeba as needed.
I started this project thinking “Just what is a GPU anyway?”. I went through many iterations with the restrictions of buying the cheapest parts available at the local stores, and using open source software and techniques for the software-side of things. The creation of the machine learning infrastructure has lead to the discovery of new server side techniques that can be applied even outside of the infrastructure. Retty also started participating in the open source community.
Having lining up at 5am in my university days at the electronics store to buy a 980 yen VHS player limited to the first customer only, to also successfully living off 800 yen worth of gas a month (日本語), I would like to think that the low cost development has been a great success. (At that price, it’d even be possible to make one server per engineer.)
And at the same time Retty’s earnings have greatly grown which has lead to an increase in the technology budget. Next year we will finally be able to make great progress on the tech side. These benefits will flow back to the engineers, the power behind the technology, further strengthening the investment.
To anyone into machine learning that wants to sink their teeth into a big data-capable desktop machine with 500 GB of memory, and to server-side engineers who would like to innovate with a machine learning infrastructure that can scale like an amoeba using the cloud: following Retty’s vision of “making the world happier, one meal at a time”, we plan to kick new development into full throttle.
Thank you for reading until the very end. Although I got really technical here, I hope this post is a Christmas present for all of the young people out there that aspire to learn machine learning. And I would also be happy if this post made you interested at all in our company. In that case, check this page out next. Thank you very much, and have a good rest of the year.
Bonus
Our PC gamer engineer Yuta building the first machine

Opened

Finished

Everyone disappointed after losing the lottery drawing for the GTX 1080

-
Since any machine can go down for maintenance and undergo changes, the idea behind this is to say that all of the files are shared between machines, so you should always make sure to create checkpoints and have functionality to restore on any other machine. It might sound like a rough way of doing things, but when done correctly it provides a low cost way to speed up innovation. Please check out the following article: https://cloudplatform.googleblog.com/2015/05/Introducing-Preemptible-VMs-a-new-class-of-compute-available-at-70-off-standard-pricing.html↩
-
akiba is what we call the Retty machine learning infrastructure.↩
-
For example, a g2.2xlarge spot instance in the AWS Tokyo region is roughly $0.15/h as of 2016/12/20.↩
-
Since the kernel module handling ceph block devices does not support snapshots for cloned block devices, we make use of a personal database stored in a VM to do what we want.↩
-
Having previously worked at a cloud-native company before joining Retty, the latest techniques in the field of infrastructure technologies felt like a completely different world to me. However, I came to realize that applying various available techniques and tweaking them to perfection lead to a significant impact on operations. So, from now on it’s my goal to try applying the latest techniques whenever possible in the future in an effort to increase operation speed even more.↩