こちらは Retty Advent Calendar 2019 より 23 日目の記事です。
昨日 22 日は Docker: 並列buildオプションの速度比較 でした。
本日は初日に続きまして 2 回目の投稿となります技術部の西村です。
Amazon Aurora 移行大全 #1 の続きとなりますので、
まだご覧になっていない方はこちらを先に読んでいただきますと幸いです。
前回は「移行準備」まで触れて終わりにしました。
- 移行対象環境の説明
- 移行の経緯
- 事前調査/検証
- 移行準備
- 並行運用
- メンテナンス作業
- 移行を終えて
今回はその続きとなります。
ともあれ移行は無事に終わったのでしょうか!
はい、無事に終わりました!!
ただ想定外なことが起こるのが世の常。どんなドラマがあったのか一部心情を交えつつ記載していきます。
移行準備
移行前の作業内容に関して Aurora 環境の作成、カスタムエンドポイント、その他事前作業という形で記載します。
Aurora 環境の作成
アプリケーション側の動作確認が済んだので移行用の Aurora 環境を作成していきます。
前回のブログ に記載しております通りテーブルスキーマの変更作業が必要になります。
通常はメンテナンスを設けて事前に master に対して作業を行うと思いますが、今回は事前メンテナンスを設けず、下記の手順で新環境を作っていく方針としました。
- 子レプリカから新規に孫レプリカ(aurora-tmp) を増やす
- aurora-tmp の read_only を OFF にする
- aurora-tmp のレプリケーション停止
- aurora-tmp に対して MyISAM => InnoDB, COMPRESS => DYNAMIC の変更作業を実施
- aurora-tmp のレプリケーション再開
- aurora-tmp から Aurora のリードレプリカを生成する
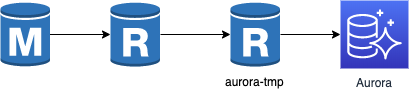
上記手順で問題なく環境は作成できました。
加えてインデックスの追加作業も aurora-tmp に対して実行しました。
多段でレプリケーションを組んでいるため、aurora-tmp がボトルネックになると悲惨です。
特にレプリカラグをシビアに気にしている弊社では致命傷になります。
そのため aurora-tmp のスペックは高めに設定し、プロビジョンド IOPS を利用して IO 性能も高めにしました。
カスタムエンドポイント
弊社ではカスタムエンドポイントを利用することにしました。
カスタムエンドポイントを利用すると負荷分散を行ってくれて、対象内のインスタンスが使用不可になると自動的に参照から切り離してくれるので、使い方によっては有用です。
ただ前回も書いたとおり、カスタムエンドポイントを編集すると一時的に使用ができない時間が発生するので注意が必要です。
本番投入前にインスタンスサイズを上げる作業を行ったのでそのときに下記の動作確認を行いました。
- インスタンスが使用不可になってからカスタムエンドポイントにて切り離されるまで
- 36 〜 40 秒程度
- インスタンスが起動して再度カスタムエンドポイントに組み込まれるまで
- 1 分 25 秒 〜 2 分 30 秒程度
ちなみにインスタンスサイズを上げて、再度利用できるようになるまで 5 〜 6 分程度かかかりました。
なおこの動作確認中に知ったのですが master 側でフェイルオーバーが発生すると各 reader も再起動が発生するようです。
DB クラスター内の DB インスタンスの再起動
その他事前作業
今回主に確認したのは下記となります。
- Route53 にて設定しているドメインの TTL
- Route53, AWS Elastic Beanstalk, Amazon ECS にて RDS インスタンスエンドポイントが直接指定されている設定の洗い出しと変更
- VPC フローログ を利用して RDS への接続元を確認
- バッチ処理の停止可否、再実行等の確認
- DB コネクションプーリング周りの挙動
- 余談ですが Amazon RDS Proxy が使えるよになると良いですね。
これを実施していくと、用途不明なものがでてきたり、別の設定漏れが発覚したりと、まぁ色々ありました。
当日メンテナンス作業をスムーズに実施するためにもここはかなり丁寧に実施しました。
並行運用
事前の準備が終わったところで、参照系の一部を本番サービスへ組み込む作業を行います。
まずは参照系の数パーセントを Aurora 環境の 1 台へ向けるようにしました。
入れる前に暖機を済ませておきます。
以降、心情含んだ文章となっております。

意気揚々と Slack に投げ込んだ私。

何もないことに安堵する私。
投入した Aurora 環境のイベントログを何気なく見ると、

「....うんうん、クラウドだからね、あるよね、そういう事。」
〜 1 時間後 〜
「....え、まじ。」

「....っお、おまえ。」
「インスタンスガチャなのか!?まじかー。」
取り急ぎサービスアウトしました。
Aurora のエラーログ確認すると segmentation fault を確認しました。
AWS サポートへ問い合わせを行い、その日は寝ることに。
〜 深夜 2 時ごろ 〜
何か感じ取って起きる。
エラーログを確認して、とあるクエリで segmentation fault していることを確認。
「なるほどー、このクエリが実行されたのか。ちょっと実行してみるか。」
クエリ実行 done!そして再起動!
「おお、このクエリ単体で再起動かかるのか。インスタンスガチャも困ったもんだ。」
「ちょっと試しに、他のインスタンスでも実行してみるか。」
クエリ実行 done!からの再起動!
「....えっ、まじ。」
試しに Aurora 環境全台クエリ実行 done! からの全台再起動!!

「ok, ok クエリ君。君と Aurora の相性が悪いようだ。」
「Aurora 2.07.0 で最新だから下げてみるか。」
「ちょうど Aurora 2.04.6 の検証環境があるからクエリ実行してみるか。」
クエリ実行 done ! からの再起動しない!
「ok, ok Aurora のなんか踏んだよ、これ。」
「検証環境を Aurora 2.07.0 にあげて再度実行してみるよ。」
「実行すると再起動するんでしょ。」
クエリ実行 done!からの再起動しない!!
「え、まじ、なんで。。」
「ok, ok ルーク、フォースを使え。」
「検証環境と本番環境でデータの差があるんだよな。」
「本番のデータを dump して再度やってみるか。」
「いやー、でも対象テーブルのデータ 4000 件くらいしか変わらないんだよね。。まぁ、やってみるか。」
Aurora 2.07.0 の検証環境にデータを投入して、
クエリ実行 done!からの再起動!
「ok, ok ルーク、だいぶ分かってきたよ。」
「Aurora 2.04.6 の環境で最新データを投入してやってみるよ。」
クエリ実行 done!からの再起動しない!
まとめると、
| 環境 | 条件 | 結果 |
|---|---|---|
| Aurora 2.07.0 | 特定クエリ データ量が一定以上 |
再起動が発生 |
| Aurora 2.07.0 | 特定クエリ データ量が一定以下 |
再起動が発生しない |
| Aurora 2.04.6 | 特定クエリ データ量が一定以上 |
再起動が発生しない |
| Aurora 2.04.6 | 特定クエリ データ量が一定以上 |
再起動が発生しない |
「いやー、これデータ量が少ないまま本番投入していたら....、こわっ」
AWS サポートに問い合わせると共に、環境を作り直すのです。
〜 再投入 〜

「よし再投入じゃ。」

「え」
「まじ。」
「いや、Aurora 再起動してないし、なんだなんだ。。」
調査すると全く関係ないアラートでした。

そうこうしていると AWS サポートから回答をいただきました。
要約すると、
Aurora MySQL Version 2.06.0 で追加された機能が原因のようである
Improvements | Aurora MySQL Database Engine Updates 2019-11-22 (Version 2.06.0) - Amazon Aurora
とのことでした。
その後は特に問題が発生しなかったため、参照系はすべて Aurora 環境へ向けました。
はい、バタバタ劇は以上となります。
心情も入って文章が拙くなってしまいましたがご了承ください。
メンテナンス作業
紆余曲折ありましたがメンテナンスが無事迎えられるまでになりました。
私が倒れても他の人が出来るまで作業手順書は作っているので何も怖くありません。
事前に切り替えられるものは切り替えたので基本的には
- メンテナンス画面
- Aurora を master へ昇格
- 動作確認
- メンテナンス解除
になります。
以下 2 の詳細について見ていきます。
接続の確認
まず master へ接続があり、更新作業が実施されている状況だと切り替えは出来ないです。
そのため接続が来ているか確認します。
$ while sleep 0.1; do mysql -u user -h rdshost -p${PASS} -e "show processlist;" | grep -viE "sleep|rdsrepladmin|system user|^Id|show processlist"; done
上記実行して確認しました。
更新が無い想定でしたが、やはり止め漏れがあって、担当者に連絡を行い対処しました。
レプリカに対しても同様の処理を行いアクセスが来てないか確認を行います。
現 master 側の接続を遮断
master 側の更新を完全に止めるためセキュリティグループを外し、特定の EC2 からのみアクセスができるようにしました。
あとは本当に接続が不可になっているか動作確認を行います。
新環境 Aurora master のレプリケーション状況を確認
上記動作確認が終われば、現 master と新 Aurora master 環境とのレプリケーション状況を確認します。
$ mysql -u user -h aurora-cluster -p${PASS} -e "show slave status\G"
複数回実行して下記を確認してました。
- Slave_IO_Running が YES
- Slave_SQL_Running が YES
- Exec_Master_Log_Pos が変化しない
- Relay_Log_Pos が変化しない
- Seconds_Behind_Master が 0 である
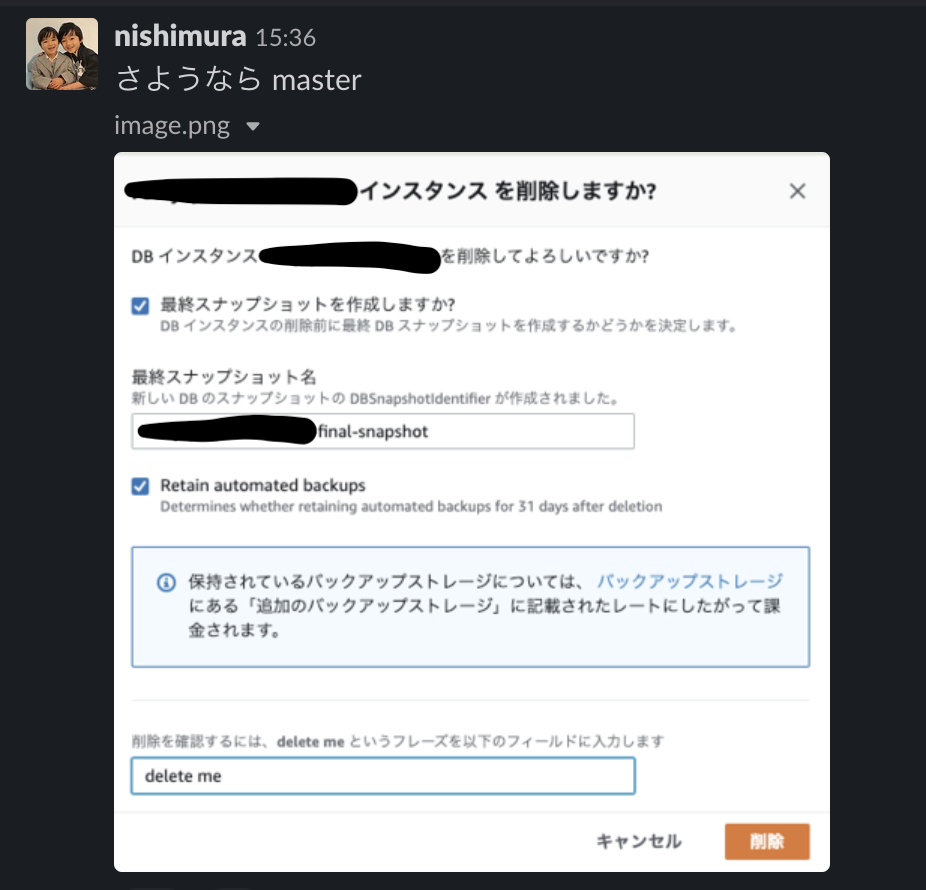
新環境 Aurora master を master へ昇格
同期が終えていることを確認したら、新環境 Aurora master を master へ昇格します。
管理画面から 昇格 を押下すると良いです。

上記出力されると独立した環境となります。
昇格を確認したら動作確認を行い、正常な挙動を確認したら、メンテナンスは完了です。
メンテナンス後は New Relic の Errors をチェックしながら通常時との変化を確認しました。
移行を終えて
抜け漏れが何点かありましたが、事前作業のおかげでスムーズに終わりました。
不測の事態も考えつつある程度のバッファを設けてスケジュールを組んでいたのですが、やはりバグなど想定外が発生すると一気に崩れますね。
今後もメンテナンスはあると思いますが、そもそもかなりの労力と時間もかかりますし、サービスを利用するユーザ様への影響もあるので、メンテナンス時間を限りなく小さくなるような設計にしていきたいと思います。
ここまで読んでいただいてありがとうございます!
明日以降の Retty Advent Calendar 2019 もどうぞよろしくお願いします!
もう仕事納めじゃ